| Each POFP (Passive Object Flow Programming)
program has an explicit input and output definition. The inter-program communication is
via passive objects. A parallel application can consist of many POFP programs
interconnected via many passive objects. The development steps are as follows:
a) Build stateless binaries. This requires composing the source program and compiling
the source program with the Synergy object library. The finished binaries must be copied
to your $HOME/bin directory.
b) Parallel program synthesis. This requires a specification of program-to-program
communication and synchronization graph. This specification links the stateles binaries
together and instructs the Synergy runtime system to dynamically generate passive object
agents.
c) Run. The program synthesis information is mapped on to the selected active
processors. Dynamic IPC agents are generated.
Parallel Program Development
Each POFP program can be coded in any convenient programming language provided each
must use Synergy API for inter-process communication and synchronization.
Current Synergy API support three passive object types: tuple space, pipe and file. The
detailed operations of for each of these object types are listed below.
a) Tuple Space object.
 | tsid=cnf_open ("name",0); It opens an object by given
"name" and returns an integer handler "tsid" for subsequent
operations. |
| length=cnf_tsread(tsid,tpname_var,buffer,switch); It reads a tuple with
name filter in "tpname_var" into "buffer". The length of a read tuple
is returned to "length" and the name of a read tuple is stored in
"tpname_var". When "switch" = 0 it performs blocking read. A -1 switch
value instructs a non-blocking read. |
| length=cnf_tsget(tsid, tpname_var,buffer,switch); It reads a tuple with
name filer in "tpname_var" into "buffer" and deletes the read tuple
from object "tsid". The length of the read tuple is returned to
"length" and the name of the read tuple is stored in "tpname_var".
When "switch" = 0 it performs blocking get. A -1 switch value instructs
non-blocking get. |
| status=cnf_tsput(tsid, "tuple_name",buffer,buffer_size) ; |
It inserts a tuple from "buffer" into "tsid" of
"buffer_size" bytes. The tuple name is defined in "tuple_name". The
execution status is returned in "status" (status < 0 means failure).
| cnf_close(tsid); It closes an object "tsid". |
b) Pipe objects.
| ppid=cnf_open("name",0); It opens an object of a given
"name". The type of the object is determined by the synthesis level.
"ppid" is the integer handler for all subsequent operations. |
| status=cnf_read(ppid, buffer, size); It reads "size" bytes of
the content in the pipe ("ppid") into "buffer". Status < 0 reports
a failure. It blocks if pipe is empty. |
| cnf_write(ppid, buffer, size); It writes "size" bytes from
"buffer" to "ppid". Status < 0 is a failure. |
| cnf_close(ppid); It closes the pipe object. |
c) File objects(sequential).
| fid=cnf_open("name",mode); It opens a file object with
"name" and mode ("r", "w", "a", "r+",
"w+"). The function returns an integer file handler for subsequent accesses. The
rest of the file operations assume identical semantics as normal Unix file operations. |
| cnf_fgets(fid, buffer) |
| cnf_fputs(fid, buffer) |
| cnf_fgetc(fid, buffer) |
| cnf_fputc(fid, buffer) |
| cnf_fseek(fid, pos, offset) |
| cnf_fflush(fid) |
| cnf_fread(fid, buffer, size, nitems) |
| cnf_fwrite(fid, buffer, size, nitems) |
| cnf_close(fid) |
d) Program termination
| cnf_term(); This call closes all objects that are not closed at this
point and exists the caller. |
e) Load balancing
| number=cnf_getf(); This call returns the f value (0<f<=100) for
load balancing control (see later section) as defined in the factor=number
clause in the CSL specification. |
| number=cnf_getP(); This call returns the number of parallel SIMD
processors at runtime. |
| number=cnf_gett(); This call returns the threshold (cut-off) value as
specified in the threhold=number clause in the CSL
specification. |
Note that all object calls become effective only after
at least one cnf_open call. This is because that the first cnf_open
initializes the caller's IPC pattern. This pattern is used in all subsequent operations
throughout the caller's lifetime.
Notes on Tuple Space Programming
Although tuple space objects can be used for many other purposes, this section only
illustrates its use for coarse grain SIMD programming. The Synergy tuple space object
differs from Linda's [2] (and Piranha's [3]) tuple space in the following:
| Unique tuples names. Synergy tuple space objects hold only unique tuples. Writing to the
same named tuple implies erasing the previous content. |
| FIFO ordering. Synergy tuples are stored and retrieved in an implicit First-In-First-Out
order. The FIFO ordering simplifies the SIMD termination control protocol (explained in
the SIMD Termination Control section). |
| Local naming convention. Tuple space names and tuple names are all local to an
application. Multiple parallel applications can use the same tuple space name or tuple
names without interference. |
Note that the cnf_tsread and cnf_tsget calls do not
require a buffer length but a tuple name variable. The actual length of a retrieved tuple
is returned after the call. The tuple name variable is over-written by the
retrieved tuple's name.
A coarse grain SIMD normally consists of one master and one SIMD worker which will be
running on many hosts employing two tuple space objects. Figure 2 illustrates its typical
software configuration.
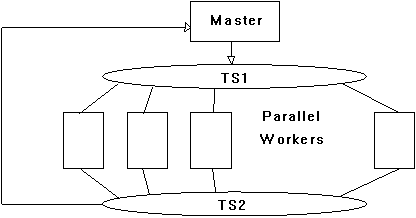
Figure 2. Coarse Grain SIMD Using Tuple Space Objects
Figure 2 is typically described by the following configuration file:

Configuration: Example;
m: Master
->f: TS1 (type = ts)
->m: Worker (type = slave)
->f: TS2 (type = ts)
->m: Master;
The above file will be used to dynamically configure
available processors for the given application.
Note that the symbols used in the configuration file (with .csl extension) MUST match
exactly with the parallel binaries (such as Master and Worker) and tuple space open
statements (such as "TS1" and "TS2").
Following is a sample sequence of tuple space object "get" (or
"read") operation:
- tsd = cnf_open("TS1", 0); /* Open a tuple space object */
- . . .
- strcpy(tpname,"*"); /* Define a tuple name */
- length = cnf_tsget( tsd, tpname, buffer, 0 );
- /* Get a tuple. Block, if non-existent. Actual tuple name returned in
"tpname".
- Retrieved tuple size is recorded in "length". */
- /* Unpacking */
- . . .
A typical tuple insertion sequence is as follows.
tsd = cnf_open("TS1", 0);
/* Packing . . . */
- /* Send to object */
- sprintf(tpname,"result%d",x); /* Making a unique tuple name */
- tplength = 8*XRES;
- if ( ( status = cnf_tsput( tsd, tpname, column, tplength ) ) < 0 ) {
- printf(" Cnf_tsput ERROR at: %s ", tpname );
- exit(2);
- }
SIMD Termination Control
In a coarse grain SIMD cluster, the master normally distributes the work tuples to one
tuple space object (TS1) then waits for results from another tuple space object (TS2, see
program frclnt in the Examples section). The stateless workers are
distributed to many computers to speed up the processing. They receive
"anonymous" work tuples from TS1 and return the uniquely named results to TS2.
They must be informed of the end of work tuples to avoid endless wait. Using FIFO tuples,
we can use sentinel to represent the ending. Upon receiving the sentinel, the worker
re-inserts the sentinel to the space and then exits itself (see program frwrk in Examples
section). This way all other workers will exit gracefully leaving the sentinel the only
tuple in the space.
In an un-ordered tuple space (such as Linda), one needs a counter to record how many
working tuple are left. Reading the counter tuples and the working tuples effectively
doubles the communication overhead since in most communication systems, creating a session
has a larger overhead than pure data transmission.
Load Balancing
Graceful termination of parallel programs does not guarantee a synchronized ending. We
found that synchronization penalty is far more significant than commonly feared
communication overhead. In an Ethernet (at most 1 megabytes per second) environment, the
communication costs per transaction is normally in seconds while the synchronization
points can run into minutes.
Synchronizing the termination points of all components is the classic "load
balancing problem". Load imbalance is caused by two factors: a) heterogeneous
computing and communication powers; and b) varying amount of work load embedded in the
distributed work tuples.
The "load balancing hypothesis" is that we can minimize the wait if we can
somehow calculate and place the "right" amount work in each work tuple.
The work tuple assignment for networked computers and loop scheduling for vector
processors are technically the same problem.
Theoretically, ignoring the communication overhead, we can minimize the waiting time if
we distribute the work in the smallest possible unit (say one loop instance per tuple).
"Load balancing" should be achieved because the fast computers will
automatically fetch more tuples than the slower ones. Considering the communication
overhead, however, finding the optimal granularity becomes a non-linear optimization
problem [10]. We looked for heuristics. Here we present the results of our studies with
the following algorithms:
| � Fixed chunking. Each tuple (work batch) contains the same
work size measured by data items. Analysis and experiments showed that the optimal
performance, assuming all data items carry the same work load, can be achieved if the work
size is 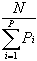 , where N is the total number of data items to be
computed, Pi is the estimated processing power measured in relative index values[10] and P
is the number of parallel workers. , where N is the total number of data items to be
computed, Pi is the estimated processing power measured in relative index values[10] and P
is the number of parallel workers. |
For example, if N=1000, Pi=1 (all processors of equal power), P=10, the optimal tuple
size is 100.
Since the measures of Pi's are never accurate, it is difficult to approach the optimal
using this algorithm without practical experiments.
| � Guided Self-Scheduling [7]. Assuming there are N data
items to be computed and P parallel workers, GSS tuple sizes are calculated according to
the following algorithm: |
- R0 = N. /* Ri: ith remaining size */
- Gi = Ri/P = ((1-1/P)i * N/P). /* Gi: ith tuple size */
- Ri+1 = Ri - Gi.
- Until Ri = 1.
For example, if N=1000, P=2, we have tuples of the following sizes:
500,250,125,63,32,16,8,4,2,1
GSS puts too much work in the beginning. It performs poorly when employing processors
with large capacity differences or computing problems with large computing density
variances between repetitions [8,9].
| � Factoring [8]. Assuming there are P parallel workers, a
threshold t>0 and a real value (0<f<=1), the factored tuple sizes are calculated
as follows: |
- R0 = N.
- Gi = Ri * f / P
- Ri+1 = Ri - (P*Gi)
- until Ri < t.
For example, if N=1000, P=2, f=0.5, t=1, we have the following tuple sizes:
250,250,125,125,63,63,32,32,16,16,8,8,4,4,2,2,1,1
Since different program input can significantly change the work distribution using the
same tuple size calculation algorithm, the presence of a "knob" (0<f<=1),
gives the programs much latitude to adapt to both input and resource status changes [12].
From our experiences, it seems that fixed chunking can always beat others after careful
tuning. This is especially true for fluctuating environments. Synergy V3.0 supports the
specification of factor(f) and threshold(t) values at application configuration time. Thus
one can tune a parallel application without re-compiling the entire system. Note that the
number of processors in a run is calculated automatically by the system.
|
|

|
|
Synergy Application Programming Interface
(API) Tuple space:
| cnf_open Each opened object has an integer handler as
return. |
| cnf_tsput Insert a tuple into an openned tuple space
object. |
| cnf_tsget Read a tuple and erase its presence in the
object. |
| cnf_tsread Read a tuple without erasing it. |
| cnf_close Close an object. |
Pipe(message queue):
| cnf_open |
| cnf_read Receive from a pipe. Block if empty. |
| cnf_write Send to a pipe. |
| cnf_close |
File:
| cnf_open |
| cnf_fread (All operations are identical to
normal Unix file operations). |
| cnf_fwrite |
| cnf_fgets |
| cnf_fgetc |
| cnf_fputs |
| cnf_fputc |
| cnf_fflush |
| cnf_fseek |
| cnf_fread |
| cnf_fwrite |
| cnf_close |
|










