Coarse Grain ParallelismThe
existence of fast processors and relatively slower inter-connection networks mandates the
need for coarse grain parallel computing. Building a perfect balanced parallel
architecture for all applications is a dream that will never become true.
While a super-fast interconnection design can accommodate many highly network demanding
tasks, given a parallel architecture, one can always find an application that can flood
the interconnection network. If the processors must use off-the-shelf operating systems,
such as Unix or NT, the situation is further worsened by the inefficiently coordinated
kernel-to-network relaying processes.
This observation implies that only heavy computing tasks with low communication
requirements (or large locality) are worthy of distributed parallel processing. The choice
is dependent on the speed of inter-connection network(s), the speed of processors and the
application requirements. Timing models are essential tools for making this choice.
Building timing models requires an understanding of the embedded parallel structures in
the application. We need a mechanism to systematically discover application dependent
parallelisms. The discovered structures should identify the most efficient way to parallel
processing the application.
Let's look at the basics for parallel processing first.
There are three entity-to-entity dependency topologies that facilitate simultaneous
processing of entities (or programs) : SIMD(Single Instruction Multiple Data),
MIMD(Multiple Instruction Multiple Data) and pipeline (Ref. Flynn). Figure 1 illustrates
their spatial arrangements and respective speedup factors.
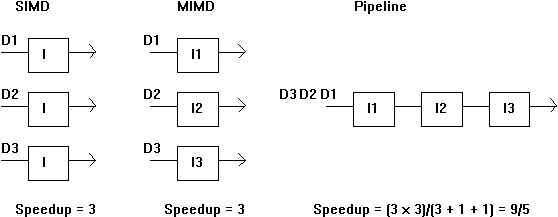
Figure 1. Parallel Topologies and Speedups
In the pipeline case, the speedup approaches 3 (the number of pipe stages) when the
number of input data items becomes large.
An application can be effectively processed in parallel only if its embedded parallel
structures are explicitly uncovered. This embedded parallel structure represents a natural
unfolding of the data dependencies of the program. Thus the most efficient processing must
not violate this structure or otherwise suffer a performance setback.
An incremental coarse-to-fine grain decomposition method (CTF) is devised to
systematically uncover coarse grain SIMD, MIMD and pipeline potentials within an
application. The method is adaptable to parallel processors employing interconnection
networks of varying speeds.
Coarse-to-fine (CTF) Parallel Application Design
The basic assumption is that the user has marked
(potentially) computing intense components in the input, either
a sequential program or algorithm in pseudo codes. The output is a set of inter-connected
POFP programs (or algorithm steps) exhibiting SIMD, MIMD and pipeline potentials.
CTF has the following steps:
a. Linear cut. This step cuts a program into segments according to user marked loops
and recursive function calls. It produces segments of three types: Sequential (S), Loop
(L, Iterative loops) and Recursive (R).
b. Merge. A pipeline with short data supplies is not an effective parallel processing
device. Therefore, it should be eliminated to save communication overhead. This step
merges linearly dependent segments to a single segment, if one does not expect long input
data streams.
c. Inter-segment data dependency analysis. This pass makes the implicit data
dependencies between decomposed (S, L and R) segments explicit.
d. L-segment analysis. The objective of this analysis is to identify one
independent and computation intensive loop amongst all nested loops. The objective is to
maximize the computation locality.
In this step, one may have to perform program transformations to remove
"resolvable dependencies". When there are more than one independent nestings,
the nesting depth of the selected loop is dependent on the number of parallel processors
and interconnection network speed. A deeper independent loop should be selected if large
number processors are connected via higher speed networks.
The result of the analysis is a three-piece partition for each L-segment: loop header
(containing pre-processing statements and the parallel loop header), loop body (containing
the computing intensive statements) and the loop tail (containing the post-processing
statements). Typically we compose a loop master consisting of a loop header and a loop
tail. The loop body is all that is needed for a loop worker.
e. R-segment analysis. The objective is to identify if the recursive function is data
dependent on the previous activation of the same function. If not, we partition the
segment into two-pieces: a master that recursively generates K*P independent partial
states, where K is an adjustable constant and P is the number of parallel processors, and
waits for results; and a worker that fetches any working batch, unwraps it, recursively
investigates all potential paths and returns results.
For optimization problems using various branch-and-bound methods, there should be some
global index tuples recording the partial optimal results. These index tuples should be
updated at most the same frequency as the initial number of independent partial states.
This treatment prevents data bleeding that would prematurely saturate the
interconnection network.
e. Coding. This step uses the results of the previous analysis to generate multiple
independent program modules communicating through passive data objects.
In selecting IPC objects, one can use tuple space objects to implement parallelizable L
and R segments (coarse grain SIMDs); pipes to inter-connect all other segments. File
objects are used only when there are multiple files to be accessed simultaneously.
Adhering to the CTF method can produce a network of modular POFP programs exhibiting
coarse grain SIMD, MIMD and pipeline potentials.
Since POFP programs use only exchanged data tuples for inter-process communication and
synchronization, these programs are totally location independent. A dataflow runtime
environment can effectively process these programs with the highest possible speed.
Performance tuning is accomplished by adjusting the size(s) of the exchanging data
elements (tuples).