
Graphs (2)
If G is weighted, its minimum spanning tree has a minimum value of total weight ∑w(u, v) [for (u, v) ∈ E'] among all spanning trees of G.
Kruskal's algorithm each time adds an edge with the least w, and connects two previously unconnected subgraphs. The algorithm uses a set to represent the vertices in a subtree, and Find-Set(u) identifies the set in which vertex u belongs.
Example:

Kruskal's algorithm is a greedy algorithm, and takes O(E lg E) time, which is the same as O(E lg V).
Prim's algorithm adds vertices into the tree one by one, according to their distance to the tree built so far, starting from a selected root r. Q is a priority queue of vertices, where for each vertex v, key[v] is the minimum weight of any edge connecting v to a vertex in the tree built so far.

Example:
Prim's algorithm also takes O(E lg V) time.
The weight of a path is the sum of the weights of the edges in the path. A shortest path is a path whose weight has the lowest value among all paths with the same source and destination. A section of a shortest path is also a shortest path.
In general, a path can be defined in graphs that are either directed or undirected, with or without cycle. However, a shortest path cannot contain cycle. Therefore, in graph G = (V, E), the shortest path contains less than |V| edges. For example, in the following graph the lengths of the shortest paths from s to each vertex is marked, plus positive and negative infinite as special cases.
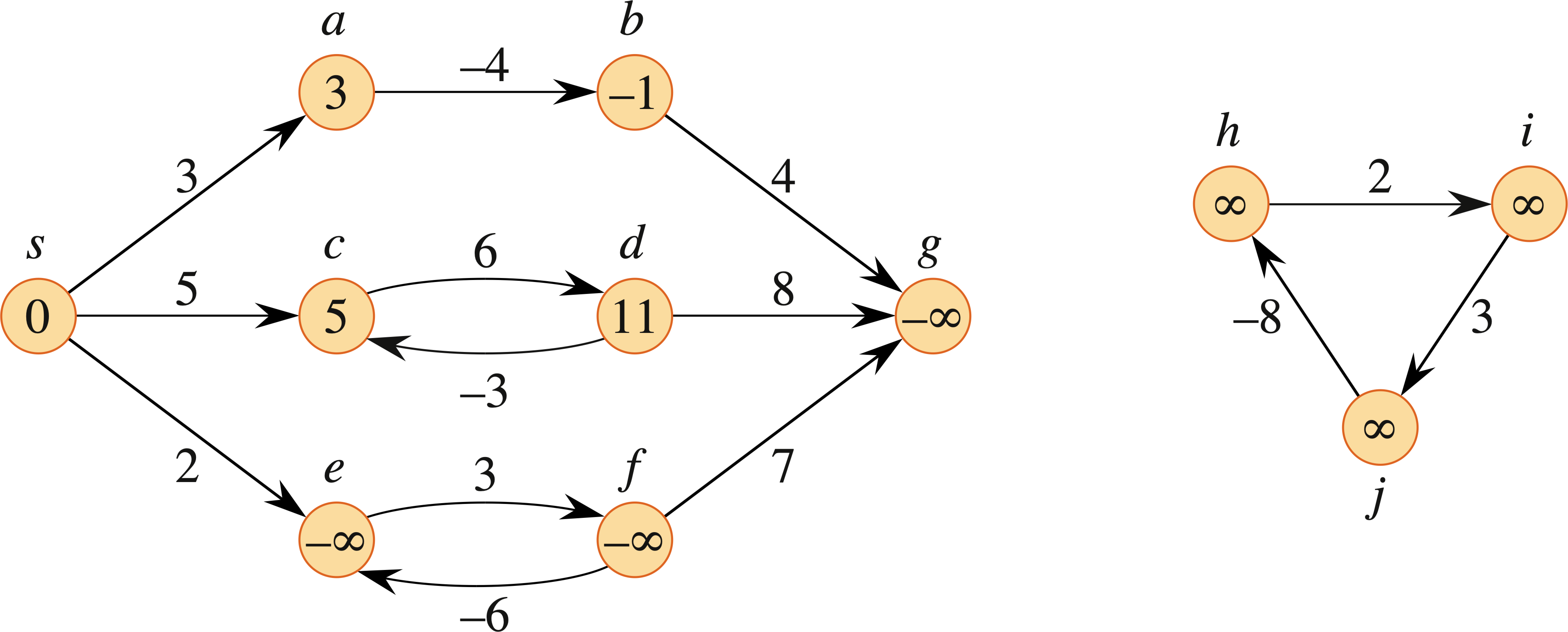
A trivial solution to the problem is to traverse the graph and enumerate all possible paths, and compare their distances. However, this solution is usually too time-consuming to be useful.
If all edges are equally-weighted, the breadth-first search algorithm BFS introduced previously finds shortest paths from a source vertex to all other vertices. However, it does not work if the edges have different weights.
To represent the shortest paths, an array d is used to record the shortest distance found so far from the source to each vertex, and an array π for the predecessor of each vertex on that path. The following algorithm initializes the data structure.
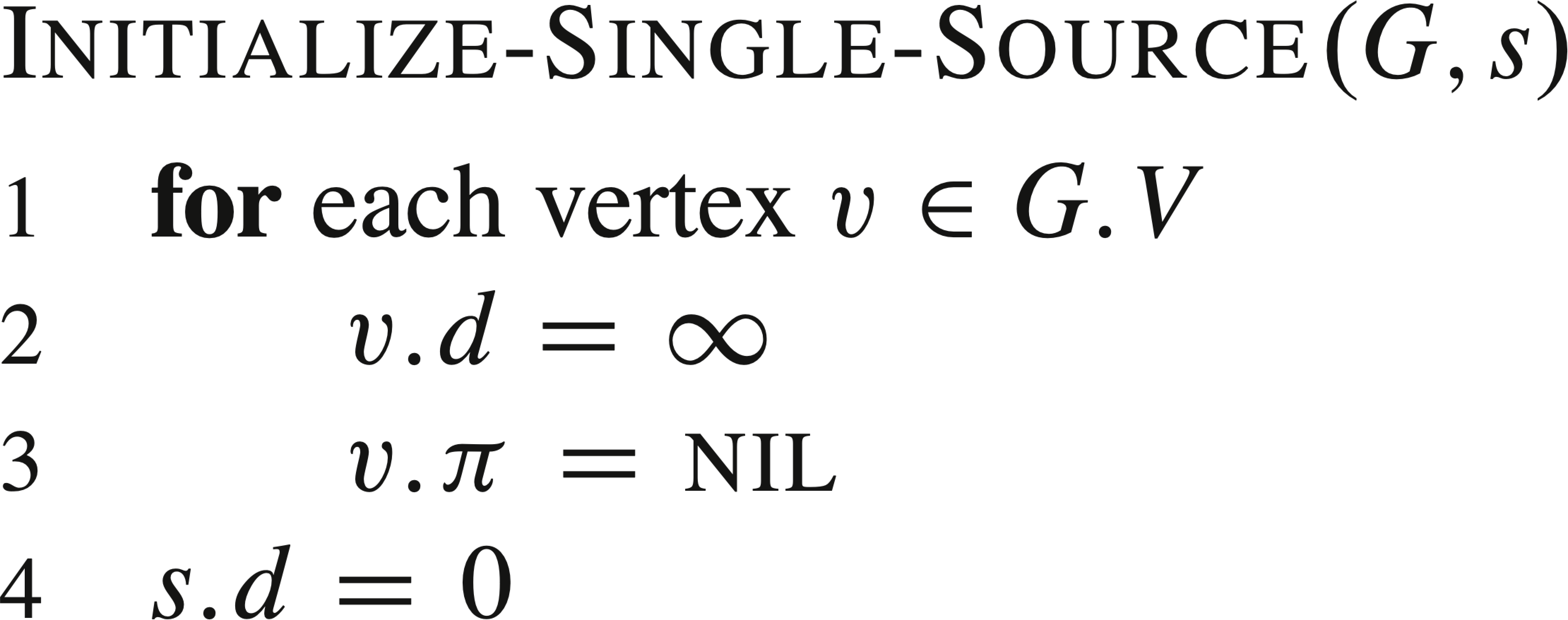
Many shortest-path algorithms use the "relaxation" step, which maintains the shortest paths from a given source to v found so far, and try to improve them when a new vertex u is taken as its predecessor. The matrix w stores the weights of the edges.
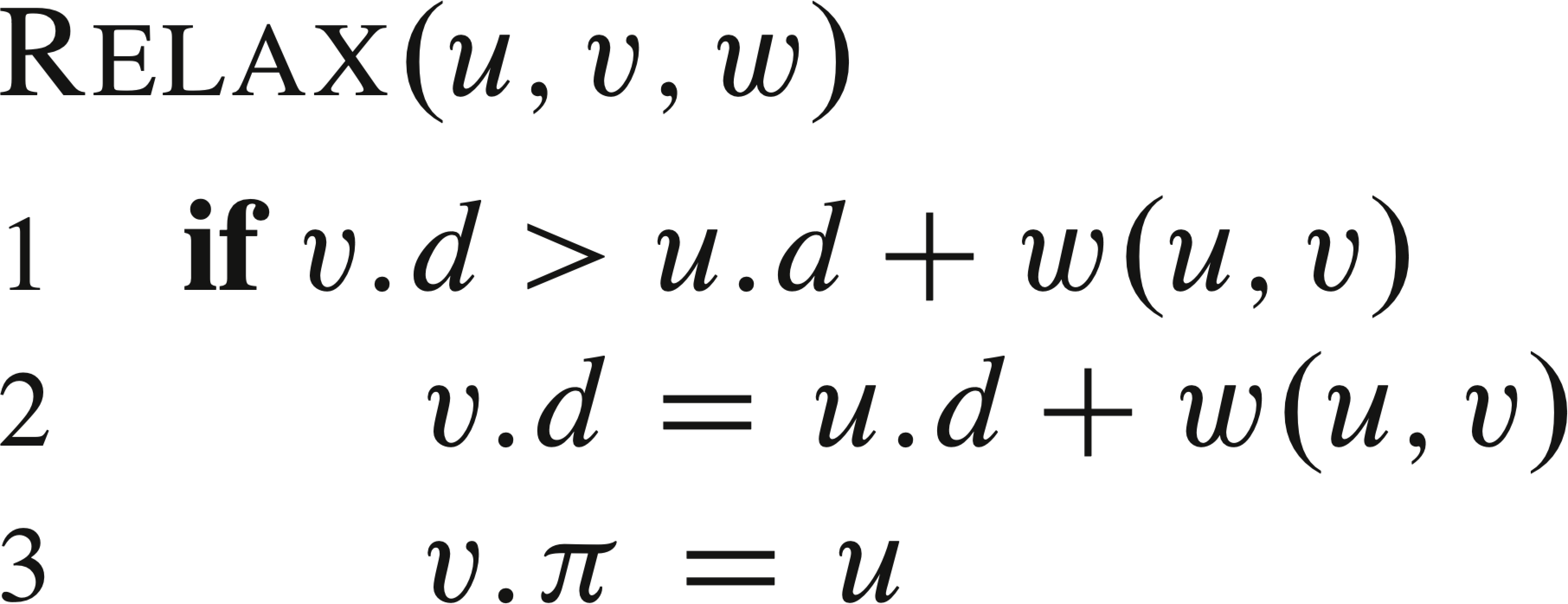
Bellman-Ford algorithm processes the graph |V| − 1 passes. In each pass, the edges are tried one-by-one to relax the distance to its ending vertex. After that, if there is still a possible relaxation, the graph must contain negatively-weighted cycle, so there is no shortest path to the involved vertices.

Example:
If the graph is a DAG, there are faster solutions. The following algorithm topologically sorts the vertices first, then determine the shortest paths for each vertex in that order. It runs in Θ(V + E) time, which comes from topological sorting (and DFS).

Example:
Dijkstra's algorithm works for weighted graphs without any negative weight. It repeatedly selects the vertex with the shorted path, and uses it to relax the paths to other vertices.

This is a greedy algorithm. Its running time is O((V + E) lg V).
Example:
If only the shortest path to a single destination is needed, stop the algorithm at that vertex. The worst-case complexity will be the same.
A new solution combines the ideas of Bellman-Ford algorithm and Dijkstra's algorithm through a recursive partitioning technique.
Many algorithms extend the weight matrix W to L that records the shortest paths found so far, plus a predecessor matrix Π, where πij is the predecessor of j on some shortest path from i to j, i.e., the last stop. Given it, the following algorithm prints the shortest path.

The following dynamic-programming algorithm extends shortest paths starting with single edges, and in each step tries to add one more edge. Here n = |V|.
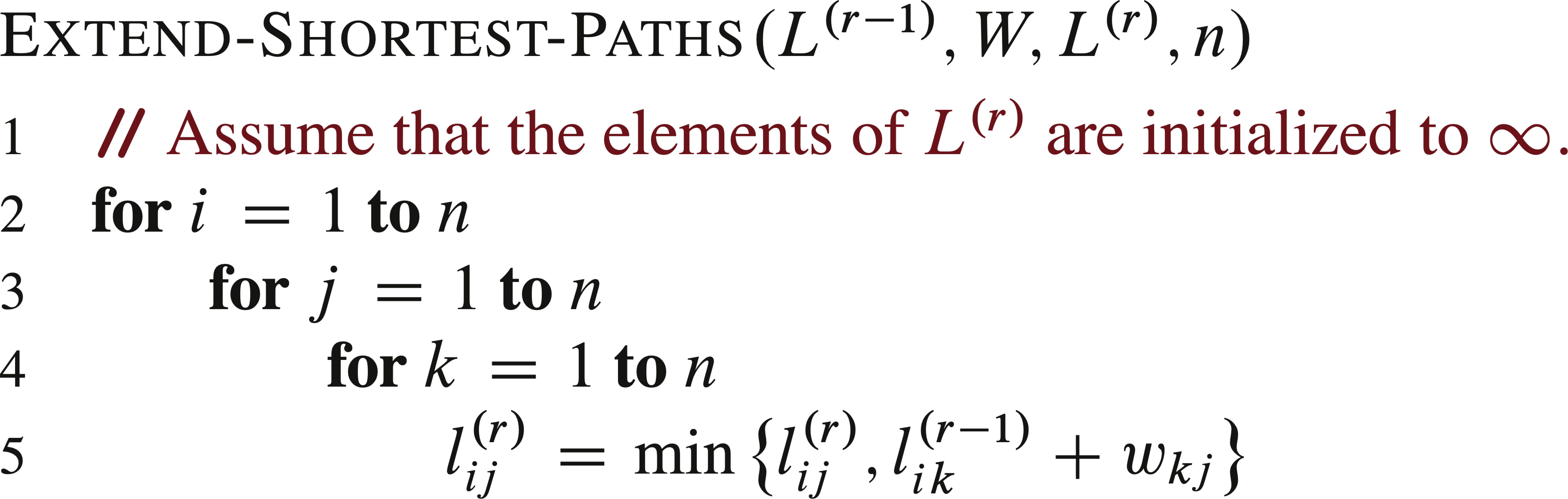

Example:

The above algorithm can be improved by updating the loop variable not as m = m + 1 but as m = 2m, and change the W in line 5 to L(m−1), so as to achieve Θ(n3 lg n) time.
Floyd-Warshall algorithm solves the problem by adding one possible intermediate vertex into the shortest paths in each step:
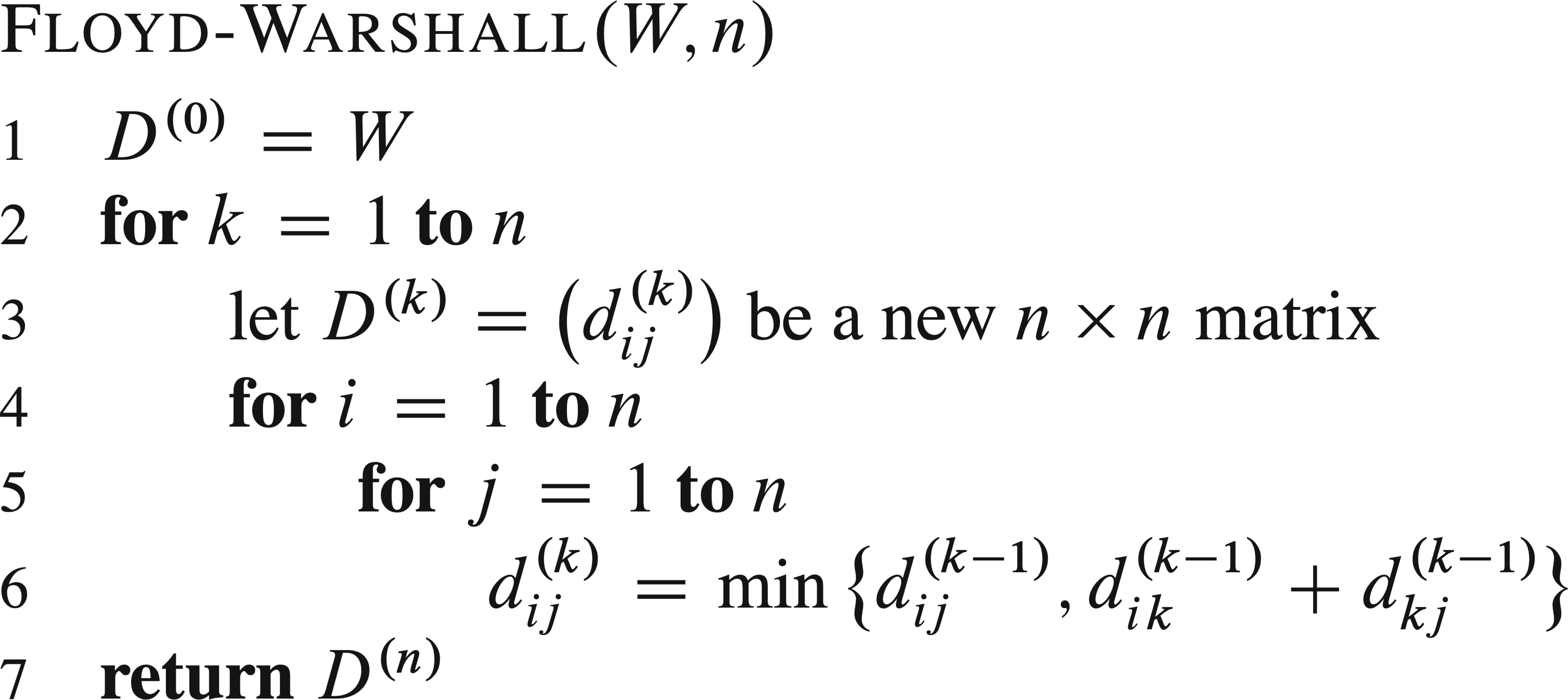
For the same problem, the intermediate results are:

The running time of the above algorithm is Θ(n3), so is more efficient than the above two.
A similar algorithm calculates the transitive closure of a graph, where T(n)ij = 1 if and only if there is a path from i to j.
![]()