Speech Recognition
Student: Chioma
Abara Professor: Dr. Pei Wang
Course: 203 Introduction to
Artificial Intelligence
Reducing Computation and
Increasing Accuracy
Speech recognition is the process by which a computer (or other type of machine) identifies spoken words. Basically, it means talking to your computer, and having it correctly recognize what you are saying.
The following definitions are the basics needed for understanding speech recognition technology:
Vocabularies
Accuracy
Training/Adaptation

The first block, which consists of the acoustic environment
plus the transduction equipment (microphone, preamplifier, anti-aliasing
filter, sample-and-hold, A/D converter) can have a strong effect on the
generated speech representations.
An utterance is the
vocalization (speaking) of a word or words that represent a single meaning to
the computer. Utterances can be a single word, a few words, a sentence, or even
multiple sentences.
Speaker dependent systems are designed around a specific speaker. They generally are more accurate for the correct speaker, but much less accurate for other speakers. They assume the speaker will speak in a consistent voice and tempo. Speaker independent systems are designed for a variety of speakers. Adaptive systems usually start as speaker independent systems and utilize training techniques to adapt to the speaker to increase their recognition accuracy. These systems are the most difficult to develop, most expensive and accuracy is lower than speaker dependent systems. However, they are more flexible.
Vocabularies (or dictionaries) are lists of words or utterances that can be recognized by the Speech Recognition system. Generally, smaller vocabularies are easier for a computer to recognize, while larger vocabularies are more difficult. Unlike normal dictionaries, each entry doesn't have to be a single word. They can be as long as a sentence or two. Smaller vocabularies can have as few as 1 or 2 recognized utterances (e.g." Wake Up"), while very large vocabularies can have a hundred thousand or more. The size of vocabulary of a speech recognition system affects the complexity, processing requirements and the accuracy of the system. Some applications only require a few words (e.g. numbers only); others require very large dictionaries (e.g. dictation machines). There are no established definitions, however
- Small vocabulary - tens of words
- Medium vocabulary - hundreds of words
- Large vocabulary - thousands of words
- Very-large vocabulary - tens of thousands of words.
Accuracy is the ability of a recognizer can be examined by measuring its accuracy - or how well it recognizes utterances. This includes not only correctly identifying an utterance but also identifying if the spoken utterance is not in its vocabulary. Good ASR systems have an accuracy of 98% or more. The acceptable accuracy of a system really depends on the application.
Some speech recognizers that have the ability to adapt to a speaker’s voice, vocabulary, and speaking style improve accuracy. When the system has this ability, it may allow training to take place. An ASR system is trained by having the speaker repeat standard or common phrases and adjusting its comparison algorithms to match that particular speaker. Training a recognizer usually improves its accuracy.
Speakers that have accents, difficulty speaking or pronouncing certain words can also use training. As long as the speaker can consistently repeat an utterance, ASR systems with training should be able to adapt.
Speech recognition systems can be separated in several different classes by describing what types of utterances they have the ability to recognize. These classes are based on the fact that one of the difficulties of ASR is the ability to determine when a speaker starts and finishes an utterance. Most packages can fit into more than one class, depending on which mode they're using.
Isolated Words
Isolated word recognizers usually require each utterance to have quiet (lack of an audio signal) on both sides of the sample window. It doesn't mean that it accepts single words, but does require a single utterance at a time. Often, these systems have "Listen/Not-Listen" states, where they require the speaker to wait between utterances (usually doing processing during the pauses). Isolated Utterance might be a better name for this class. An isolated-word system operates on single words at a time - requiring a pause between saying each word. This is the simplest form of recognition to perform because the end points are easier to find and the pronunciation of a word tends not affect others. Thus, because the occurrences of words are more consistent they are easier to recognize.
Connected Words
Connect word systems or connected utterances are similar to Isolated words, but allow separate utterances to be "run-together" with a minimal pause between them. A continuous speech system operates on speech in which words are connected together, i.e. not separated by pauses.
Continuous Speech
Recognizers with continuous speech capabilities are some of the most
difficult to create because they must utilize special methods to determine
utterance boundaries. A continuous speech system operates on speech in which
words are connected together, i.e. not separated by pauses. Continuous speech
is more difficult to handle because of a variety of effects. First, it is
difficult to find the start and end points of words. Another problem is
"co-articulation". The production of each phoneme is affected by the
production of surrounding phonemes, and similarly the start and end of words
are affected by the preceding and following words. The recognition of
continuous speech is also affected by the rate of speech (fast speech tends to
be harder). Continuous speech recognizers allow users to speak almost
naturally, while the computer determines the content. Basically, it's computer
dictation.
Spontaneous Speech
There appears to be a variety of definitions for what spontaneous speech actually is. At a basic level, it can be thought of as speech that is natural sounding and not rehearsed. An ASR system with spontaneous speech ability should be able to handle a variety of natural speech features such as words being run together, "ums" and "ahs", and even slight stutters.
Although any task that involves interfacing with a computer can potentially use ASR, the following applications are the most common right now.
Dictation
Dictation is the most common use for ASR systems today. This includes medical transcriptions, legal and business dictation, as well as general word processing. In some cases special vocabularies are used to increase the accuracy of the system.
Command and Control
ASR systems that are designed to perform functions and actions on the system are defined as Command and Control systems. Utterances like "Open Netscape" and "Start a new xterm" will do just that.
Telephony
Some PBX/Voice Mail systems allow callers to speak commands instead of pressing buttons to send specific tones.
Medical/Disabilities
Many people have difficulty typing due to physical limitations such as repetitive strain injuries (RSI), muscular dystrophy, and many others. For example, people with difficulty hearing could use a system connected to their telephone to convert the caller's speech to text.
Embedded Applications
Some newer cellular phones include C&C speech recognition that allows utterances such as "Call Home". This could be a major factor in the future of ASR.
Sound Cards
Because speech requires a relatively low bandwidth, just about any medium-high quality 16-bit sound card will get the job done. You must have sound enabled in your kernel, and you must have correct drivers installed.
Sound cards with the 'cleanest' A/D (analog to digital) conversions are recommended, but most often the clarity of the digital sample is more dependent on the microphone quality and even more dependent on the environmental noise. Electrical "noise" from monitors, PCI slots, hard-drives, etc. are usually nothing compared to audible noise from the computer fans, squeaking chairs, or heavy breathing.
Some ASR software packages may require a specific sound card. It's usually a good idea to stay away from specific hardware requirements, because it limits many of your possible future options and decisions. You'll have to weigh the benefits and costs if you are considering packages that require specific hardware to function properly.
Microphones
A quality microphone is key when utilizing ASR. In most cases, a desktop microphone just won't do the job. They tend to pick up more ambient noise that gives ASR programs a hard time.
Hand held microphones are also not the best choice because they can be cumbersome to pick up all the time. While they do limit the amount of ambient noise, they are most useful in applications that require changing speakers often, or when speaking to the recognizer isn't done frequently (when wearing a headset isn't an option).
The best choice, and by far the most common is the headset style. It allows the ambient noise to be minimized, while allowing you to have the microphone at the tip of your tongue all the time. Headsets are available without earphones and with earphones (mono or stereo).
It is essential to turn up the microphone volume for optimum results. For Linux, this can be done with a program such as XMixer or OSS Mixer and care should be used to avoid feedback noise. If the ASR software includes auto-adjustment programs, use them instead, as they are optimized for their particular recognition system.
Computers/Processors
ASR applications can be heavily dependent on processing speed. This is because a large amount of digital filtering and signal processing can take place in ASR.
With CPU intensive software, usually, faster is better. More memory is, of course, good. It is possible to do some SR with 100MHz and 16M RAM, but for fast processing (large dictionaries, complex recognition schemes, or high sample rates), a minimum of a 400MHz and 128M RAM is better. Because of the processing required, most software packages list their minimum requirements.
A wide variety of techniques are used to perform speech recognition. There are many types of speech recognition, as well as levels of speech recognition, analysis, and understanding.
Typically speech recognition starts with the digital sampling of speech. The next stage is acoustic signal processing. Most techniques include spectral analysis; e.g. LPC analysis (Linear Predictive Coding), MFCC (Mel Frequency Cepstral Coefficients), cochlea modeling and many more.
The next stage is recognition of phonemes, groups of phonemes and words. This stage can be achieved by many processes such as DTW (Dynamic Time Warping), HMM (hidden Markov modeling), NNs (Neural Networks), expert systems and combinations of techniques. HMM-based systems are currently the most commonly used and most successful approach. Most systems utilize some knowledge of the language to aid the recognition process. Some systems try to "understand" speech. That is, they try to convert the words into a representation of what the speaker intended to mean or achieve by what they said.
Recognition systems can be broken down into two main types. Pattern Recognition systems, which compare patterns to known/trained patterns to determine a match. Acoustic Phonetic systems which, use knowledge of the human body, such as speech production and hearing to compare speech features like, phonetics (e.g. vowel sounds). Most modern systems focus on the pattern recognition approach because it combines with current computing techniques and tends to have higher accuracy.
Most recognizers can be broken down into the following steps:
- Audio recording and Utterance detection
- Pre-Filtering (pre-emphasis, normalization, banding, etc.)
- Framing and Windowing (chopping the data into a usable format)
- Filtering (further filtering of each window/frame/freq. band)
- Comparison and Matching (recognizing the utterance)
- Action (Perform function associated with the recognized pattern)
Although each step seems simple, each one can involve a multitude of different, and sometimes completely opposite, techniques.
(1) Audio/Utterance Recording: can be accomplished in a number of ways. Starting points can be found by comparing ambient audio levels (acoustic energy in some cases) with the sample just recorded. Endpoint detection is harder because speakers tend to leave "artifacts" including breathing/sighing, teeth chatters, and echoes.
(2) Pre-Filtering: is accomplished in a variety of ways, depending on other features of the recognition system. The most common methods are the "Bank-of-Filters" method, which utilizes a series of audio filters to prepare the sample, and the Linear Predictive Coding method, which uses a prediction function to calculate differences (errors). Different forms of spectral analysis are also used.
(3) Framing/Windowing: involves separating the sample data into specific sizes. This is often rolled into Pre-Filtering or Additional Filtering. This step also involves preparing the sample boundaries for analysis (removing edge clicks, etc.)
(4) Additional Filtering: which is not always present, is the final preparation for each window before comparison and matching. Often this consists of time alignment and normalization.
(5) Comparison and Matching: There are a large variety of techniques available for comparison and matching. Most involve comparing the current window with known samples. There are methods that use Hidden Markov Models (HMM), frequency analysis, differential analysis, linear algebra techniques, spectral distortion, and time distortion methods. All these methods are used to generate a probability and accuracy match.
(6) Actions: can be just about anything the developer wants.
The digital audio is a stream of amplitudes, sampled at about 16,000 times per second. It’s a wavy line that periodically repeats while the user is speaking. While in this form, the data isn’t useful to speech recognition because it’s too difficult to identify any patterns that correlate to what was actually said.
To make pattern recognition easier, the PCM digital audio is transformed into the "frequency domain." Transformations are done using a windowed fast-Fourier transform. The output is similar to what a spectrograph produces. In frequency domain, you can identify the frequency components of a sound. From the frequency components, it’s possible to approximate how the human ear perceives the sound.
The fast Fourier transform analyzes every 1/100th and converts into the frequency domain. Each 1/100th of a second results is a graph of the amplitudes of frequency components, and describing the sound heard for that 1/100th of a second. The speech recognizer has a database of several thousand such graphs, called a codebook, that identify different types of sounds the human voice can make. The sound is "identified" by matching it to its closest entry in the codebook, producing a number that describes the sound. This number is called the "feature number." (Actually, there are several feature numbers generated for every 1/100th of a second but the process is easier to explain assuming only one.)
Audio is inherently an analog phenomenon. Recording a digital sample is done by converting the analog signal from the microphone to a digital signal through the A/D converter in the sound card. When a microphone is operating, sound waves vibrate the magnetic element in the microphone, causing an electrical current to the sound card (think of a speaker working in reverse). Basically, the A/D converter records the value of the electrical voltage at specific intervals.
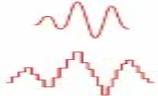
Top: analog sound wave. Bottom: digitized sound wave
There are two important factors during this process. First is the "sample rate", or how often to record the voltage values. Second is the "bits per sample", or how accurately the value is recorded. A third item is the number of channels (mono or stereo), but for most ASR applications mono is sufficient. Most applications use pre-set values for these parameters and users shouldn't change them unless the documentation suggests it. Developers experiment with different values to determine what works best with their algorithms.
So what is a good sample rate for ASR? Because speech is relatively low bandwidth (mostly between 100Hz-8kHz), 8000 samples/sec (8kHz) is sufficient for most basic ASR. But, some people prefer 16000 samples/sec (16kHz) because it provides more accurate high frequency information. For most ASR applications, sampling rates higher than about 22kHz is a waste.
And what is a good value for "bits per sample"? 8 bits per sample will record values between 0 and 255, which means that the position of the microphone element is in one of 256 positions. 16 bits per sample divides the element position into 65536 possible values.
Similar to sample rate, if you have enough processing power and memory, go with 16 bits per sample. For comparison, an audio Compact Disc is encoded with 16 bits per sample at about 44kHz.
The encoding format used should be linear signed or unsigned. Using a U-Law/A-Law algorithm or some other compression scheme will usually use up computing power.
Voice Verification/Identification
Some ASR systems have the ability to identify specific users. Speaker recognition is the process of automatically recognizing who is speaking on the basis of individual information included in speech signals. It can be divided into Speaker Identification and Speaker Verification. Speaker identification determines which registered speaker provides a given utterance from amongst a set of known speakers. Speaker verification accepts or rejects the identity claim of a speaker - is the speaker the person they say they are?
Speaker recognition technology makes it possible to a the speaker's voice to control access to restricted services, for example, phone access to banking, database services, shopping or voice mail, and access to secure equipment.
Both technologies require users to "enroll" in the system, that is, to give examples of their speech to a system so that it can characterize (or learn) their voice patterns.
In an ideal world, you could match each feature number to a phoneme. If a segment of audio resulted in feature #52, it could always mean that the user made an "h" sound. Feature #53 might be an "f" sound, etc. If this were true, it would be easy to figure out what phonemes the user spoke.
Unfortunately, this doesn’t work because of a number of reasons:
- Every time a user speaks a word it sounds different. Users do not produce exactly the same sound for the same phoneme.
- The background noise from the microphone and user’s office sometimes causes the recognizer to hear a different vector than it would have if the user were in a quiet room with a high quality microphone.
- The sound of a phoneme changes depending on what phonemes surround it. The "t" in "talk" sounds different than the "t" in "attack" and "mist".
- The sound produced by a phoneme changes from the beginning to the end of the phoneme, and is not constant. The beginning of a "t" will produce different feature numbers than the end of a "t".
The background noise and variability problems are solved by allowing a feature number to be used by more than just one phoneme, and using statistical models to figure out which phoneme is spoken. This can be done because a phoneme lasts for a relatively long time, 50 to 100 feature numbers, and it’s likely that one or more sounds are predominant during that time. Hence, it’s possible to predict what phoneme was spoken.
For the speech recognizer to learn how a phoneme sounds, a training tool is passed hundreds of recordings of the phoneme. It analyzes each 1/100th of a second of these hundreds of recordings and produces a feature number. From these it learns statistics about how likely it is for a particular feature number to appear in a specific phoneme. Hence, for the phoneme "h", there might be a 55% chance of feature #52 appearing in any 1/100th of a second, 30% chance of feature #189 showing up, and 15% chance of feature #53. Every 1/100th of a second of an "f" sound might have a 10% chance of feature #52, 10% chance of feature #189, and 80% chance of feature #53.
The probability analysis done during training is used during recognition. The 6 feature numbers that are heard during recognition might be:
52, 52, 189, 53, 52, 52
The recognizer computes the probability of the sound being an "h" and the probability of it being any other phoneme, such as "f". The probability of "h" is:
80% * 80% * 30% * 15% * 80% * 80% = 1.84%
The probability of the sound being an "f" is:
10% * 10% * 10% * 80% * 10% * 10 % = 0.0008%
Given the current data, "h" is a more likely to be produced.
The speech recognizer needs to know when one phoneme ends and the next begins. Speech recognition engines use a mathematical technique called "Hidden Markov Models" (HMMs) that figure this out. Assume that the recognizer heard a word with an "h" phoneme followed by an "ee" phoneme. The "ee" phoneme has a 75% chance of producing feature #82 every 1/100th of a second, 15% of chance feature #98, and a 10% chance of feature #52. Notice that feature #52 also appears in "h". If you saw a lineup of the data, it might look like this:
52, 52, 189, 53, 52, 52, 82, 52, 82, etc.
So where does the "h" end and the "ee" begin? From looking at the features you can see that the 52’s are grouped at the beginning, and the 82’s grouped at the end. The split occurs someplace in-between. Humans can eyeball this. Computers use Hidden Markov Models. The speech recognizer can figure out when speech starts and stops because it has a "silence" phoneme, and each feature number has a probability of appearing in silence, just like any other phoneme.
At this point, the recognizer can recognize what phoneme was spoken if there’s background noise or the user’s voice had some variation. However, there’s another problem. The sounds of phoneme changes depend upon what phoneme came before and after. You can hear this with words such as "he" and "how". You don’t speak a "h" followed by an "ee" or "ow", but the vowels intrude into the "h", so the "h" in "he" has a bit of "ee" in it, and the "h" in "how" as a bit of "ow" in it.
Speech recognition engines solve the problem by creating "tri-phones", which are phonemes in the context of surrounding phonemes. Thus, there’s a tri-phone for "silence-h-ee" and one for "silence-h-ow". Since there are roughly 50 phonemes in English, you can calculate that there are 50*50*50 = 125,000 tri-phones. That’s just too many for current PCs to deal with so similar sounding tri-phones are grouped together.
Finally, the sound of a phoneme is not constant. For example, a "t" sound is silent at first, and then produces a sudden burst high frequency of noise, which then fades to silence. Speech recognizers solve this by splitting each phoneme into several segments and generating a different senone for each segment. The recognizer figures out where each segment begins and ends in the same way it figures out where a phoneme begins and ends.
Reducing Computation and Increasing Accuracy
The speech recognizer can now identify what phonemes were spoken. If the user spoke the phonemes, "h eh l oe", then you know they spoke "hello". The recognizer should only have to do a comparison of all the phonemes against a lexicon of pronunciations. This is not as simple as it may sound.
- The user might have pronounced "hello" as "h uh l oe", which might not be in the lexicon.
- The recognizer may have made a mistake and recognized "hello" as "h uh l oe".
- Where does one word end and another begin?
- Even with all these optimizations, the speech recognition still requires too much CPU.
To reduce computation and increase accuracy, the recognizer restricts acceptable inputs from the user. The following describe some reasons why this is feasible:
- It’s unlikely that the user will speak, "supercalifragilisticexpialidocious" since it’s not a valid word.
- The user may limit him/her-self to a relatively small grammar. There are millions of words, but most people only use a few thousand of them a day, and they may need even fewer words to communicate to a computer.
- When people speak they have a specific grammar that they use. After all, users say, "Open the window," not "Window the open."
- Certain word sequences are more common than others. "New York City" is more common than "New York Aardvark."
Context Free Grammar
One of the techniques to reduce the computation and increase accuracy is called a "Context Free Grammar" (CFG). CFG’s work by limiting the vocabulary and syntax structure of speech recognition to those words and sentences that are applicable in the application’s current state.
The application specifies the vocabulary and syntax structure in a text file. The text file might look like this:
<Start> = ((send mail to) | call) (Fred | John | Bill) | (Exit application)
This grammar translates into seven possible sentences:
Send mail to Fred
Send mail to John
Send mail to Bill
Call Fred
Call John
Call Bill
Exit application
Of course, the grammars can be much more complex than this. The important feature about the CFG is that it limits what the recognizer expects to hear to a small vocabulary and tight syntax.
There are many factors involved in speech recognition. Although speech recognition technology seems relatively new, computer scientists have been continually developing it for the past 40 years. They’ve made great strides in improving the systems and processes, but the futuristic idea of your computer hearing and understanding you is still a long way off. However, there are numerous on-going projects that deal with topics such as the following:
· Visual cues to
help computers decipher speech sounds that are obscured by environmental noise
· Speech-to-speech translation project for spontaneous
speech
· Multi-engine Spanish-to-English machine translation
system
· Building synthetic voices
When I started on my endeavor to create a small HTML editor to demonstrate command vs. dictation in creating a web page, I thought it would be easier than it actually was. I imagine that the pioneers of speech recognition technology figured that this neat and feasible idea couldn’t be that complicated to accomplish. It’s nearly 50 years since the first attempts and there have been major successes in this aspect of artificial intelligence and I believe there will be many more to come.
References:
http://www.yorvic.york.ac.uk/~cowtan/fourier/fourier.html
http://psych.hanover.edu/Krantz/sen_tut.html
http://www.zdnet.co.uk/pcmag/supp/1998/speech/
http://www.academicpress.com/csl
http://cslu.cse.ogi.edu/asr/#ASR
http://cslu.cse.ogi.edu/tutordemos/nnet_training/tutorial.html
http://www.w3.org/TR/grammar-spec/
http://cslu.cse.ogi.edu/toolkit/old/userguide/cslush/cslush.html#appendix:worldbet