Communication and Language
In AI study, communication may happen between two computer systems, or between a computer and a human being. The language used may be
The techniques can be broadly classified in two general approaches: symbolic and statistical. It is important to note that these approaches are not mutually exclusive. In fact, the most comprehensive models combine these techniques. The approaches differ in the kind of processing tasks they can perform and in the degree to which systems require hand-crafted rules as opposed to automatic training/learning from language data.
(1) The symbolic approach has the closest connection to traditional linguistic models. It divides the understanding process into the following major steps:
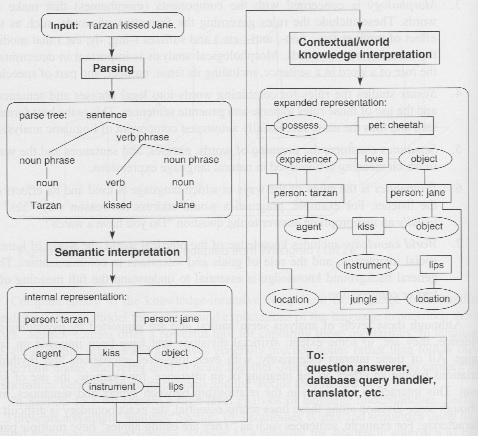
Symbolic models provide a capability for detailed analysis of linguistic phenomena, but the more detailed the analysis, the more one must rely on hand-constructed rules, which is difficult to design.
A free ebook: Prolog and Natural-Language Analysis
(2) The statistical approach uses large corpora of language data to compute statistical properties such as word co-occurrence and sequence information.
For instance, one approach uses the probability of a word with certain properties following a word with other properties. This information can be estimated from a corpus that is labeled with the properties needed, and used to predict what properties a word might have based on its preceding context.
Although limited, this kind of models can be surprisingly effective in many tasks. For instance, a model involving part of speech labels (e.g., noun, verb) can typically accurately predict the right part of speech for over 95 percent of words in general text.
Statistical models are not restricted to part of speech tagging, however, and they have been used for semantic disambiguation, structural disambiguation (e.g., prepositional phrase attachment), and many other properties.
A big advantage to statistical techniques is that they can be automatically trained from language corpora. The challenge for statistical models concerns how to capture higher-level structure, such as semantic information, and structural properties, such as sentence structure.
The companion website of the book "Foundations of Statistical Natural Language Processing"
The information provided to a language generator is produced by some other system (the "host" program), which may be an expert system, database access system, machine translation engine, and so on.
Natural language generation can be divided into two major stages: content selection ("What shall I say?") and content expression ("How shall I say it?"). Processing in these stages is generally performed by so-called text planners and sentence realizers, respectively.
When what to say is determined, the different types of generation techniques can be classified into the following categories:
Human-Machine Interfaces. Given the increased availability of computers in all aspects of everyday life, there are immense opportunities for defining language-based interfaces. A prime area for commercial application is in telephone applications for customer service, replacing the touch-tone menu-driven interfaces with speech-driven language-based interfaces. Example: speech recognition in Windows
Information Retrieval and Information Extraction. While most web-based search techniques today involve little more than sophisticated keyword matching, there is considerable research in using more sophisticated techniques, such as classifying the information in documents based on their statistical properties (e.g., how often certain word patterns appear) as well as techniques that use robust parsing techniques to extract information. Example: IBM Watson
Machine Translation. The goal is to provide rough initial translations that can be post-edited. The naive "dictionary plus grammar book" approach does not work. Jokes: "Out of sight, out of mind" became "Invisible idiot", and "The spirit is willing, but the flesh is weak" became "The vodka is good, but the meat is rotten". With the progress of NLP, in applications where the content is stylized, such as technical and user manuals for products, it is becoming feasible to produce reasonable-quality translations automatically. Examples: Google translate, IBM speech-to-speech