By Michael Hunter for Dr. Pei Wang, CIS 203 fall 2001, student class ID: c203105
Table of contents
IntroductionThe Importance of Being Earnest: Non-visual clues in Recognition
The Difference Between Vision and Recognition
When will I see you again? Learning and Remembering
Seeing is Believing: Knowledge and Context
Permutations, Rotations and Reflections
Eureka! I have found it………probably… Conclusion
Vision and Recognition
Human recognition depends upon many variables. Take for example the act of recognizing another human being of your acquaintance. Imagine that you are walking down the street, and see another human being approaching you from far away. At first, the distance would make immediate recognition of the person impossible. You may not be able to distinguish the sex of the person from a great distance, yet you immediately begin a recursive recognition process.
The first thing that you recognize is that the object is human. Next, you will try to determine if the human being is approaching you or moving away from you. Next you might access the threat likelihood. For example, if you are a fugitive and the person approaching is a policeman, you may wish to make evasive maneuvers rather than continue the recursive process. On the other hand, if you are also a policeman, you may wish to get closer and continue the process until you have identified the object as a particular associate.
In both cases, you may recognize the police uniform even before you determine the sex. As the distance shrinks, you will continue to make many discrete observations about the object including its sex, size, skin color, hair color, gait, etc. At some point in time you are face to face with another human being that you either recognize or do not. If the person is only a casual acquaintance whom you have met only a few times long ago, you may even have to speak with him before you can complete the recognition process. Besides the voice of the person, you may use the location of the encounter as an aid to memory. If you are in New York, then you might naturally concentrate on the New York police-persons of your acquaintance, and ignore memories of policemen you met in Hong Kong. Human beings use much more that vision alone in the act of recognition. In Oscar Wilde's farce The Importance of Being Earnest and in many other tales, it is non-visual clues that lead to recognition.
In our simple example, the object was recursively recognized as a member of a subset of the previous step in the recognition process. It may have proceeded something like this:
Notice that the set of human males is not a true subset of large humans. However, if the universe under consideration is composed only of large humans, then those who are male may be considered a subset of large human beings. Another way of looking at this is that large males are a set formed by the intersection of the set of males and the set of large people. Such distinctions may seem trivial, but they are not. They are central to the problem of recognition by machines.
At each step we must make a decision about the next set to test against. A recognized object must be an element of every set that contains it or any of its ancestors. In effect, we are searching for a match. When we think of search algorithms it is natural to think of graphs. If each vertex represents the subset containing itself and all its descendant vertices, and each leaf is an individual object, and the weights on each edge are the number of elements in the vertex below it, then the optimal testing sequence is the minimum spanning tree for the graph. Thus in this sense, the recognition process may be viewed as a search problem. [1] We search our memory to see it the object we are viewing is identical to an object that we have viewed before and if so we recognize it. If the object has no match, we add it so that it can be recognized later. Deleting old or infrequently accessed objects conserves memory.
We have established that recognition is a recursive process. An object is recursively classified by membership in a subset of objects. At each step we 'recognize' the object as a member of a subset. The subset may be the subset of objects that we have never seen before. Thus we can know that we do not recognize someone. Typically, if the last subset contains exactly one element identical to the object of inquiry we claim that we recognize it. Thus if our goal was to meet Mom at the supermarket, we know that she is the only possible match no matter how many women are shopping at the time. If none of the human objects is a match for Mom, we know that she isn't present. We do not conclude that she doesn't exist. We may, however, in the process of our search decide that a certain woman at the far side of the store might be Mom if she is approximately Mom's size and shape. It is possible to assign a probability to the proposition that this woman is Mom, and based upon this probability, select her as a candidate for further investigation.
We can narrow a search for a particular object from among many objects using probabilistic techniques. The final result of recognition, however, may not admit a probabilistic solution. After investigation, we would never say that there is a 90% probability that the woman is Mom. Either she is Mom, or she is not. In many situations, we do not accept anything less than certainty as recognition. In other situations, particularly when we are not discussing human beings, a probabilistic solution is completely reasonable.
Now consider another scenario, we are at a public place with our family, but have become separated from them. If we wish to gather together with all of the family, then the first step is locate one member. Now we want to search for a member of a subset, the subset of human beings that contains our family as members. If we can recognize any one element in this subset, then we may use the same procedure recursively to find the remaining members. For each member, the process is similar to finding Mom in t he supermarket. We begin by assigning probabilities to narrow the search, and we end by positive identification of a particular object as a member of the set. We continue until all of the objects in the subset are present.
Recognition is the precondition for correct response to any object in a universe where the set of objects under consideration has more than one member. It will now be useful to consider the relationship between the number of objects in a universe and the minimum number of features necessary to distinguish each object within it.
If our universe has only 2 objects then we need only 1 bit of information that must be different for each to distinguish them apart. If our universe has three objects we require 2 bits and so on.... This table gives the first few numbers in the sequence. Obviously, N bits can code for 2N objects provided that a unique vector of bits identifies each object.
If our universe is restricted to only 2 dimensions, then recognition is pattern matching. Pattern matching at the very simplest is expressed in code such as
if ( eq x 3 ),
then do something
What we expect from this is that the value of x is compared to the value 3. In binary machines, the value in x and the value 3 are both stored as vectors of 1s and 0s. If the vectors are identical, then ( eq x 3 ) is true. Like text and numbers, any two-dimensional image can be broken down into a set of vectors. In video images, a view is composed of an array of pixels each of which has properties such as color, intensity, brightness, etc. To recognize that two images are the same it is only necessary to compare vectors. Many clever data structures and algorithms have been developed for this purpose. Some computer languages, such as Perl have an advanced pattern-matching syntax using regular expressions. Scientists at the Human Genome Project us e sophisticated pattern matching software.
When the universe under consideration has three dimensions the complexity of the problem grows. To study this I begin with something I call "the minimal visual feature set 3D recognition problem." The simplest possible object in a 3 dimensional universe is a cube. If a single visual feature, say color, is used as the basis for distinguishing between 2 cubes and two cubes have the same color pattern, then the objects cannot be distinguished. At minimum the cubes must have 2 colors but just having 2 colors is not enough.
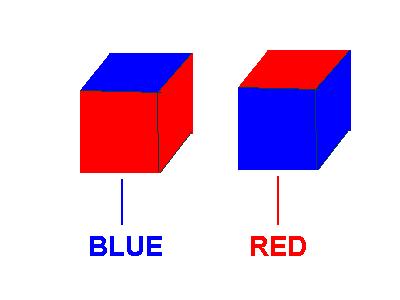
Consider 2 cubes each side of which possesses exactly one color attribute, and an automaton that can examine the cubes and distinguish between the colors. Then if the first cube, call it cube 1, has 5 sides of the first color, call it color A, and one side of the second color, call it color B, and the second cube, cube 2, also has 5 sides of color A and 1 side of color B, then cube 1 and cube 2 remain indistinguishable. If the number of sides with color A is 2 for both cubes, then they can be distinguished ONLY if the two sides of color A are adjacent on one cube and opposite on the other. [see diagram 1] In fact, under these restrictions the maximum number of distinguishable cubes is two. Here is a diagram.
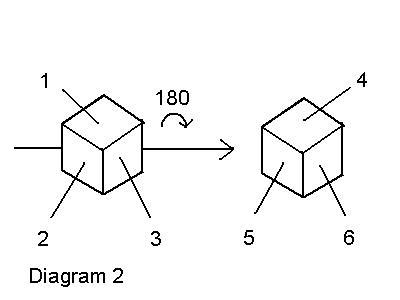
Notice that our automaton needs both additional knowledge and additional capabilities to make this distinction. In 3D space, a human being can only view 3 sides of an opaque cube simultaneously. If our automation also "sees" with a pair of closely spaced visual sensors, then it will suffer from the same limitation. In order to see all sides of a cube it is necessary to rotate the cube exactly once by 180o. [see diagram 2]
We see immediately that if the number of "color A" sides on "cube 1" is not equal to the number of "color A" sides on "cube 2", they are distinguishable. At most 4 cubes can be distinguished by "color count." Although 2 cubes, both with 3 "color A" sides and 3 "color B" sides cannot be distinguished by count, they can be distinguished if the 3 sides of a color meet at a point on "cube 1" and in 2 parallel lines on "cube 2." The last distinction, like the case of 2 "Color A" sides touching and not touching, makes use of the special properties of a 3D space and requires a rotation of 180o.
The sequence given for the maximum number of recognizable objects is also more complex than in 2 dimensional universes.
From these simple examples we can begin to distinguish
The Difference Between Vision and Recognition
Vision is a term that has a multitude of meanings in English, all related in some sense to the term light. The human eye detects a range of frequencies of light as color. When those frequencies are reflected by the surface of objects we perceive shapes. Two eyes give us depth perception. Most meanings of vision imply more than just the perception of color, shape, and depth. Some meanings are metaphorical others imply recognition. Machine vision can mean different things too. It can be as simple as detecting the intensity of light for phototropic automatons or as complex as detecting minute changes in the reflectivity of a surface on a microscopic scale. It can include the detection of electromagnetic frequencies beyond the range of human perception, such as ultraviolet and infrared.
Recognition, while closely related to vision in humans, can be achieved without vision. Blind persons can recognize others by sound, smell, or touch. The basis any act of recognition is memory. In human minds, memory is extended by categorization of objects. If I pick up a cube that I have never seen before, I can nevertheless recognize that I am holding a cube. Recognition is closely related to pattern matching and search. It may use vision alone as input, as in the case of our automaton that distinguishes between cubes. It may use vision in combination with other characteristics or bypass the perception of light entirely.
The act of recognition by human beings often requires movement of either the perceiver or the perceived object. We will often pick up an object and manipulate it before the process is complete. If the object is large, we may move our bodies instead of the object. We already know that the robot in our Cube-Universe needs to rotate cubes. Thus some process that makes sense of the effects of movement may be a prerequisite of recognition.
In the "real world" and in many problem domains, Objects change with time.
Accounting for such changes greatly increases the complexity of recognition. Even something as simple as viewing someone in direct sunlight and then trying to recognize them later when they are in shadow is surprisingly complex. Some objects, such as plants, grow in size while others, such as ice cubes, shrink in mass. This means those memories about size, shape and weight are useful only when combined with knowledge about time and expected changes. Similarly, an object can smell or feel differently at different times.
Another source of difficulty is cause by The Effects of Multiple "Effectors."
If I am alone in my universe, then the location of objects would be sufficient to distinguish among them. Automatons that require such solitude would not be considered intelligent by most definitions. If there are other entities in the universe cap able of modifying objects, then even reasonably good knowledge of expected changes may be insufficient for success. In toy problems we may structure our universe so that we are always able to uniquely distinguish each item. This is completely impossible in an unbound universe.
Recognition includes some interesting special cases such as recognizing Me, Myself, I. If I hold my hand before my face and you hold your hand next to it, I will always be able to distinguish my hand from yours. Even if m y vision is not acute, I can recognize my part because of a feedback loop. When I will my hand to move in a particular way, and it responds, I obtain feedback knowledge sufficient for recognition.
A similar feedback loop can assist me in another special case, which I call the Mirror in the Bathroom. A mirror is reflects an image that could be an imaginary image of me or of someone else whom I recognize. T he same feedback loop used to identify my hand can be used to identify my reflection. It can be used to determine the presence of mirror in front of me. Reflections of other objects are not so easy. If I know that a mirror is in front of me, I may surmise that the objects I see are reflections, but if I do not have such information, and I cannot see myself in the mirror, I may be as easily fooled as a fool in a funhouse.
When will I see you again? Learning and Remembering
If the universe to be recognized is too large to store knowledge about everything in it, then learning, remembering, and forgetting things becomes necessary. When there are many variables in my universe, I will need some mechanism to help in ordering my necessarily limited memories. As I have already mentioned, old or infrequently accessed memories can be discarded to free memory for new objects. Additionally, not all newly observed objects are as important as some older ones. A relative not seen for several years may still be more important to recognize than a piece of junk mail that arrived yesterday. A system for prioritizing memories is important.
Seeing is Believing: Knowledge and Context
In the "the minimal visual feature set 3D recognition problem," we want a "robot" that can recognize a cube by its colored faces alone. To do so, it must grasp the cube and rotate it 180 degrees. Before a robot could perform the grasping, lifting and rotation, it needs to "know" that such a sequence would provide the data necessary for identification of the object. Then it has to know how to perform each step. First it must perceive the object, then it must position itself relative to the object. If the universe of a robot contains objects other than just cubes, then the methods of perception, positioning and grasping are more complex. The robot may have to determine a suitable location on the object to grasp. It may require greater range of motion. It may be impossible for the robot to know in advance which sequence of operations is the minimum required for recognition.
Methods for determining how to position myself relative to some object for the purpose of grasping the object fall into the domain of robot control. They share a similarity to the problem of recognizing rotations of a pattern.
Permutations, Rotations and Reflections
Recognition of rotations and reflections of objects is important for other reasons besides positioning. If there are other effectors in my environment, then objects may be re-positioned by one of them. If this is the case, how can I distinguish between new objects that I am seeing for the first time and known objects that have been rotated? First, I must "know" that rotation is a possibility. Then I need to generate permutations of the object and make comparisons.
An extension of the eight queens problem, a traditional project for computer science students, will serve to illustrate the discovery of rotations and reflections. First, write a program to get a solution to the eight queens problem. Here it is:
Given a chessboard, a square divided into 64 smaller squares, alternating black and red; and the legal moves of a queen in chess, a queen can move any number of squares in a straight line along her row, her column or her diagonal. The problem consists of arranging 8 queens on a chessboard such that no queen can kill another in a single move. In any solution, no 2 queens share the same row, column or diagonal.
Since the colors are a visual aid and otherwise irrelevant, they can be ignored and a chessboard can be represented as a matrix or two-dimensional array.
In 'C' define a two dimensional array of characters:
char chessboard [8][8];
We'll initialize to all blanks, then store a 'Q' in each array element where a queen is located.
Now we need to figure out what constitutes a vector, that is a row, column or diagonal of squares.
If the chessboard is labeled with rows 1, 2, 3,..., 8 and columns A, B, C,..., H, then each square is identified by its row/column combination: 1A, 2A, 3A,...,8H. To simplify the job, we use a slightly different map that requires no translation into array indices. We will still identify each square using a row-column pair, but we'll use the numbers from 0 to 7 for both rows and columns. The top left square then becomes chessboard[0][0] and the bottom right becomes chessboard[7][7]. Then each square, chessboard[R][C], shares a row with all other squares with the same [R] and a column with all other squares with the same [C]. For example chessboard[2][0] and chessboard[2][7] are in the same row, while chessboard[0][3] and chessboard[7][3] are in the same column.
Next we determine a test to see which squares share a diagonal. For forward diagonals (/)which are oriented 45 degrees to the right, it's simple. Each square on the same forward diagonal has the same sum when the Row index [R] and column index [C] are added. For backward diagonals (\) which are oriented 315 degrees from the column axis, we can achieve the same effect by simply subtracting the row index from 7 before summing. In terms of array indices [R][C], all squares on a diagonal with the square identified as chessboard[R][C] will satisfy one of the following formulas:
chessboard[R + n][C + n]
chessboard[R + n][C - n]
chessboard[R - n][C + n]
chessboard[R - n][C - n]
for some integer n, 0 < n < 8. The converse is not true. Some squares defined by the above formulas will be "off the board" relative to chessboard[R][C]. To be "on board", bot h indices must fall within range 0 < index < 8.
A solution to our problem can be defined as a set of 8 coordinate pairs: S={(a,b),(c,d),(e,f),(g,h),(i,j),(k,l),(m,n),(o,p)}
where a,b,c,...p are members of the set N={0,1,2,...7}
And the set S also meets the following constraints:
a ≠ c ≠ e ≠ g ≠ i ≠ k ≠ m ≠ o
and b ≠ d ≠ f ≠ h ≠ j ≠ l ≠ n ≠ p
and no pair (R,C) in the solution set S is related to any other pair (X,Y) by a diagonal formula i.e.
if pair (R,C) in the solution, then all pairs (X,Y) are EXCLUDED from the solution if
(X,Y) = (R + n, C + n)
(X,Y) = (R + n, C - n)
(X,Y) = (R - n, C + n)
(X,Y) = (R - n, C - n) where n is an integer ≠ 0.
Now we can write functions to tell us when two elements are on the same row, column or diagonal.
My first step when writing any algorithm is to determine what the algorithm needs to know in advance and what it needs to "remember". In the 8 queens problem, we need to keep track of the number of queens we've placed on the board and the locations where we've stored them. We know that there are 8 queens, 8 rows and 8 columns, so it is self -evident that there will be one queen in each row and column. Begin with chessboard[0][0]. We know that some square, chessboard[0][N], N = 0,1,...7, will have a Q in the solution.
In pseudocode, a first attempt at a solution might look like this:
Unfortunately, this algorithm does not work. We run through 8 iterations and find no solution. No matter which column gets our first 'Q', following the path of next legal square never gets all 8 queens on the board. This illustrates a well-known problem: how do we prove an algorithm correct? In our example problem, we know that at least one solution exists and it must have a queen in the first row (row 0), so if an algorithm fails to find a solution, it is obviously incorrect. But if an algorithm is required to determine if a solution to a problem exists, we need other criteria to determine the validity of the algorithm.
Fortunately, in the eight queens problem, a solution proves the algorithm, not the other way around. What we need is a method to place and remove queens in a systematic way until a solution is reached. Working row by row, if we place our first queen at chessboard[R][C], we will eliminate two or three squares from the next row. This leaves us with five or six possible legal squares in the next row. If we choose one of these and continue, we again find multiple choices. Repeating this process will necessarily terminate in one of two outcomes: either some row will contain no legal spaces or the last row will contain exactly one legal space and the puzzle is solved.
At each point where a choice of legal squares is available, there is insufficient information to determine which, if any, leads to a solution. Our only option is to choose systematically until one of the two known outcomes is obtained. If the choice ends in success, no problem, but if it ends in an empty row with no legal squares, then we must backtrack one or more rows until a different choice is possible. Fortunately, we have an excellent tool for this purpose: a stack. A stack data structure, where the last item added is the first item removed, can be used as a primitive memory. Combined with our indices, counter, and functions, it will enable us to determine how many queens to remove and which choice to make next.
In 'C', the coordinate pair would be collected into a struct, so that pairs could be pushed onto or popped from the stack as a unit:
struct copair{
unsigned short row;
unsigned short column;
};
This also simplifies the functions for testing, since we can now pass two pointers to coordinate pairs as in this function to test if two coordinates are on the same row::
bool sameRow(struct copair *a, struct copair *b){
if(a->row == b->row)
return(true);
return(false);
}
The stack can be implemented as a linked list. Then, by "walking" the list and using our comparison functions, we determine if the coordinate pair under scrutiny conflicts with any pair already on the stack. In C++ or Java, it would surely become a class. In 'C' it is just another struct and a set of associated functions to add and remove elements:
struct node{
struct copair *pcp; /* pointer a copair struct */
struct node *next; /* pointer to next node in list */
};
struct node *push(struct node *pTop, struct copair *pcp);
struct node *pop(struct node *pTop);
Note that each node contains two pointers, so you must allocate and de-allocate storage.
In pseudocode:
If you followed all that, you may have realized that when numQueens reaches the number 8, the stack contains the coordinate pairs of the solution and we no longer need the two-dimensional chessboard array. The coordinate pairs are still used, but the storage is superfluous. This method works, but is not very efficient. Solutions are found by systematically trying legal permutations until the set of permutations is exhausted. To arrive at the first solution, 113 squares are pushed onto the stack, 105 of these are subsequently popped. To get all 92 requires 1951 pushes and 1943 pops. This algorithm has another advantage: if we save the solution set, pop queens from the stack and decrement numQueens until another choice is legal, and continue on from that point as though no solution had been obtained, we will find additional solutions.
To directly "see" the need for systems of classification, consider again the eight queens program. Our algorithm has a number of limitations. Even if we modify it, as described above, to collect all the additional solutions. It still reveals nothing about the solution space. Is the set of solutions complete? Does it contain redundancies? Is there a pattern shared by all solution sets? What effect does our definition of a solution have on the results? What effect, if any, does our coordinate pair system have on the nature of the solutions?
To address the last question first, using coordinate pairs to represent cells in a table or squares on a board has a definite effect. For Example:
The solution sets
S1 = {(0,4),(1,6),(2,0),(3,2),(4,7),(5,5),(6,4),(7,1)} and
S2 = {(0,5),(1,0),(2,4),(3,1),(4,7),(5,2),(6,6),(7,3)}
appear to be different solutions to the problem, but in fact, S2 is generated from S1 by a 90o rotation. In terms of our chessboard, no queen would need to be moved relative to the board, only the "names", (the coordinates), of the cells are changed.
The impact of our definition of a solution now becomes clear. By our original definition given above, where a solution is a set of coordinate pairs, S1 and S2 are two distinct solutions. To someone with 8 queens on a chessboard, S1 and S2 are the same solution viewed from two different angles. S2 is therefore redundant. Since we're dealing with squares, each unique solution will have at least four distinct sets of coordinate pairs associated with it. A set will be determined by the corner of the square chosen to be (0,0). This accounts for rotation of the board in one plane, but there are other views. To visualize this, imagine that our chessboard is made of glass with etched lines and that our queens are just sticky stars of the type applied to children's schoolwork. Imagine a star in each square of a solution set. Now pick the board up and turn it upside down. (The same effect can be achieved with a mirror.) If you now label the squares with coordinate pairs as before, you will find that the solution set is distinct from the previous four. If you rotate the board 90o, 180o, and 270o without lifting and re-label each time, you generate three more sets of coordinate s. The total number of sets of coordinate pairs is now 8 for a single arrangement of queens.
Our algorithm reveals none of this, since it is predicated upon the notion that queens can be moved, but the coordinate system (the board) is fixed. We can construct our program to provide all 92 coordinate pair sets that satisfy the problem. We can then devise functions to partition the 92 into sets representing rotations, mirrors and mirrors of rotations. Each of the resulting 12 partitions holds the "aliases" of a distinct solution. These 12 distinct solutions have interesting properties. Firstly, if there are 12 distinct solutions, why are there not 96 (= 12 x 8) permutations? The answer is that one of our partitions contains only 4 "aliases" because the solution is diagonally symmetric.
Another interesting feature is that 7 of the 12 generate the same geometric pattern, or a rotation or mirror of the same pattern when a square with a solution is "tiled". To see this, place identical solution squares from one of the 7 partitions side by side on a plane, corner to corner, so that each corner of each solution square shares exactly one point with the corners of three other solution squares. A discernable pattern will immediately immerge which was not obvious when looking at a single solution square. Now imagine a transparent 8x8 square, a "window square", which floats over this plane and which you can shift by row, column or diagonal over the fixed grid of solution squares. Not all positions of the window will reveal a solution below, but by shifting the window, rotation or reflection, all 56 "aliases" in the 7 partitions can be found, regardless of which solution square you used to construct the plane. The remaining 5 partitions generate distinct patterns when tiled, so no single pattern space supplies all solutions.
This puzzle demonstrates the inter-relatedness of predicate assumptions, definition of a solution, and the choice of data structures. Our data structures can effect our predicate assumptions, or vice versa.
Pattern Recognition
Recognition builds upon pattern recognition and search. Donald R. Tveter titled his book on the subject The Pattern Recognition Basis of Artificial Intelligence. [3] Even such sophisticated techniques such as shape morphing rely ultimately on permutations. [2] Obtaining a solution to a permutation problem and even obtaining all solutions is significantly easier than proving that you have obtained all solutions. For proof, you need inference, specifically deduction, and first order predicate logic. Combine this with some statistics and probability theory and we may be able to say that some image has a 99% probability of being a particular object of our acquaintance. If we want an algorithm that discovers patterns that hide behind perceived phenomena, then we need inductive reasoning as well. We need the full AI toolbox if we want to recognize objects and infer new predicates about them.
Our colored cube universe told us something about minimums. The eight queens problems told us something about rotations and reflections. An image can be partitioned into smaller sub-images. If there are many sub-images that each have a color of composed of red, green and blue, then we get something analogous to image representation on a computer monitor. The greater the number of pixels, the higher the resolution. What about more general objects, steel parts for example, that may all be a single color? Obviously, something besides color is required. There are a number of different approaches.
If a bright light is shined upon a three dimensional object from one side, the other side is in shadow. The intensity of light reflected by the object can be quantified using a grayscale. If grayscale values are assigned to each sub-image, then a matrix of grayscales is a representation of the image that can be rotated or mirrored like the chessboard in the eight queens problem. If the angle of a unidirectional light source is known, trigonometric functions can be used to derive information about the features of the object. The edges of faceted objects are associated with a sharp transition of intensity along a line or curve.
An enormous amount of research has been devoted to edge detection. In 2 dimensional images, edges may lie at the intersection of an object with its background (the intersection of the object with air), they may lie entirely within the boundaries of the object, or they may intersect other edges. Objects can have edges hidden from view. Edges can be behind or in front of other edges. Edges can be represented as vectors. Their intersections are the solutions to linear equations.
Edges bound planes. Planes naturally divide an image into regions. The juxtaposition of regions can be used to classify objects or sub-objects within images. Gradients can distinguish planes from the shadows of other planes. Gradients are also necessary to capture a curved surface. One interesting method of contour detection uses the shape of the "Nearest Neighbor Set" of pixels. This algorithm makes use of fact that "if a pixel belongs to a contour, then the shape of its NN-set will differ from one found in an homogenous region." [4] Decision rules are used to classify pixels.
Another interesting set of approaches uses projection techniques. If an object is positioned at certain angle relative to a background and a unidirectional light source is positioned opposite the background, then the shadow of the object gives a profile of the object. If a grid of lines is projected onto a curved object, they will curve and intersect at angles determined by the curvature of the surface. Measurement of projected light may be suitable in some very controlled universes.
In any collection of edges that contains them, we will most likely want to classify intersections, especially corners. This is because corners are the most information rich feature in the shape of an object. Traditional corner detection algorithms use graylevels, a technique called bileveling, and trigonometric functions. Graylevels are particularly sensitive to noise. [5] Some algorithms use exterior edges and corners to construct a wire-frame approximation of the image. Others use the edges and their intersections to construct "solid" models. Wire-frames are easier to morph than solids. On the other hand, solid object modelers have their own distinct advantages.
If an object is modeled by building up solid object primitives whose volume is known then the volume of the entire object is the sum of the volumes of the primitives. This type of solid modeling has several sub-types. The four most important are "cellular decomposition", "spatial occupancy", "set-theoretic", and "boundary representation." In "cellular decomposition", objects are built up of regular polyhedrons. In "spatial occupancy enumeration" they are modeled using little cubes or spheres. "Set-theoretic" uses a set of shapes that can be multiplied by either a positive or negative scalar. "Boundary representations" use the spatial relationship of edges and corners. [6]
In both wire-frame and solid models the set of possible views form a set. In the cube universe previously discussed we learned that 2 is the minimum number of views required to "see" all sides of cube. The maximum number of views is easily approximated. It is obvious that 2 cubes of the same size are indistinguishable based on shape alone, no matter which methods of shape detection and classification are used. The act of recognition depends upon the classification. If I can recognize a cube of a certain size, then I can recognize all cubes of that size as members of a set. I may be unable to uniquely identify each cube, but I can distinguish all cubes in the set from an object that is not a member. For many applications this is sufficient.
Significantly, if any shape-representation of a 3-dimensional object is rotated about an axis, the set of views is equivalent to the output of a continuous function. The function will of course depend upon both the representation and the chosen axis. For small objects that can be lifted and rotated, the number of choices for an axis of rotation can be reduced by always selecting the longest (or shortest) axis visible. During the process of rotation, the changes in the length of edges or the area of planes are calculated and data is then used to construct the function. Once a function is generated, all objects that satisfy the function have the same shape.
Eureka! I have found it………probably…
One distinct advantage that machines have over human beings is that the number of light detectors is not limited to two. A machine with 3 "eyes" can use triangulation for shape detection. Machines can also be constructed to "see" using frequencies of the electromagnetic spectrum outside the ranges perceptible by human senses. However, no matter how many features we measure, classify and store, no matter how complex or sophisticated our algorithms and analysis, the number of recognizable objects will always be a finite number.
If the number of objects in the universe is not limited, then absolute certainty in recognition is impossible. If such is the case, the best that we can hope to achieve is a very high degree of probability that some particular object is "what we think it is." Even in the case of human beings, absolute certainty is doubtful. Many persons have been convicted upon eyewitness testimony only to be found innocent after DNA testing was performed. In such cases the "certainty" of the eyewitness was sufficient for conviction, but the eyewitness was wrong nonetheless. "Common sense" is sufficient to show that the probability of misidentification is inversely proportional to "how well" we know the object under scrutiny. If I know you well, then I have recognized you many times before and the probability that I correctly recognize you now increases.
A full discussion of probability is outside the scope of this paper, but probabilistic methods are required in any universe where the number of distinguishable objects is very large.
This paper barely scratches the surface of the recognition problem. The body of published research is huge and growing. The applications are significant now, and as better recognition systems are developed, I have no doubt that the number and importance of such applications will increase. Today we cannot build an artificial intelligence capable of recognizing the same number of objects as a normal four-year old human being. Whether or not we ever achieve such generality does not in any way limit the importance of more narrow applications. Machines today "recognize" users by their passwords, tomorrow it may be by card reader or biometric devices. Human lives may be extended and improved by cancer "recognition" programs such as Autopap, a program that scans pap smears (images) looking for cancer. It is likely that applications will be developed that no one has yet imagined. Data mining applications may discover new patterns that fundamentally change science or medicine. Time will tell; meanwhile, there is enough exciting work for many lifetimes.
{kind=link}
{kind=link}