Recently it has been recognized that GPUs can carry out at high speed data parallel operations and more in general it has become possible to carry out General-Purpose computing on Graphic Processing Units (GPGPU or GP2). Usually GPUs are dedicated to graphic tasks like pixel shading, or a mixture of graphic and computing tasks, now have appeared GPUs that just do computing. In this discussion we will focus on the GPUs by NVIDIA and the C extension, Compute Unified Device Architecture (CUDA) used to program them. Since there are over 100M NVIDIA cards in use, your computer may have one so that you can experiment with CUDA.
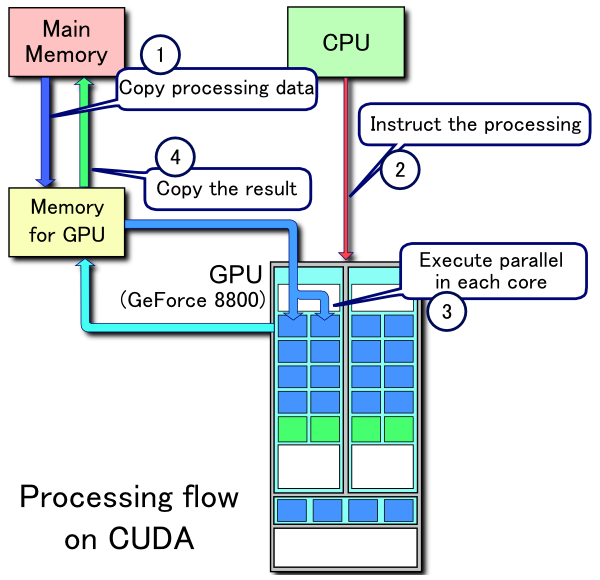
The following chart describes the processing of a CUDA program:
where
A GPU ( a GPU is what we mean by "device", and a system might have multiple devices) will consist of a
number, say 30, of multiprocessors (MP or SM,
for Streaming Multiprocessor), each
with a number, say 8, of cores or Streaming Processors (SP). Thus we have
a total of say 240 SP. An SP has hardware to hold the state of 3 batches
of threads (a batch is called a warp) each usually with 32
threads.
The SM follows a Single Instruction Multiple Threads
(SIMT) policy, i.e a single
instruction is executed by all the
threads in a Warp. The SM scheduler manages warps and
will execute a SIMT instruction as
soon as a warp is ready and resources are available.
Thus we have 30 SM * 8 SP * 3 Warps * 32
threads = 23020 potentially ready threads of these
of which up to 30 SM * 32 threads in warp = 960 could
be executing in physical concurrency [but there are delays due to the
memory]. If threads in a warp do not all execute the same instruction
[perhaps because a conditional has a different result in different threads
of the warp] then the warp will be partitioned and the partitions will be
executed in turn i.e. at one time all the executing threads of a warp must
be executing the same instruction.
A warp contains threads with consecutive, increasing thread ID.
The reader accustomed to P-threads or any thread encountered
when discussing concurrency in a traditional
operating systems course will be amazed about the threads discussed in CUDA,
which are extremely light weight.
So light that we are told that the creation of 32 threads
takes place in 1 clock cycle, that thread scheduling takes no clock
cycles!
Each core has the hardware as registers and local memory to preserve the
status of each of its threads, that is why there is no
overhead for context switching.
By the way, the speed of these processors, so as to reduce the power
consumption and heat, is kept at around 1.5Ghz.
A CUDA program consists of code that will be executed on the host and code that will be executed in the device(s). The device code is launched by the host and is organized as a grid which is a one or two dimensional array of Blocks which in turn are one, two, or three dimensional arrays of threads with at most 512 threads in total per block. A device can execute a single grid at a time. A block will be executed on a single SM, and an SM may hold multiple blocks executing concurrently if resources allow. Each thread executes a C function that is called a kernel. All the threads of a grid execute the same kernel. A kernel is just a plain C function, with the qualifier "__global__" and a few restrictions. Among them:
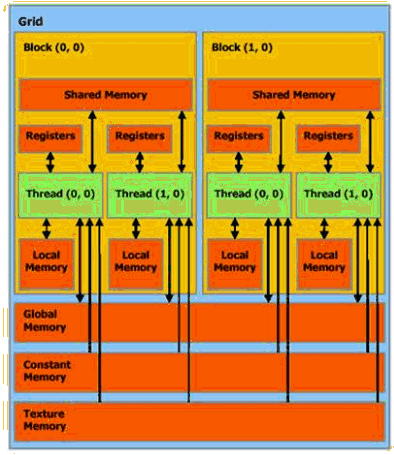
Diagram of CUDA Memory hierarchy
Characteristics of CUDA memories
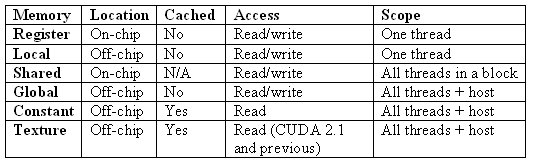
We have spent some time describing the architecture and performance of the GPU because it helps understand how CUDA is executed, and how to increase its performance. But the aim of CUDA is to reduce hardware dependency in parallel programming, less dependency on the specifics of the GPUs.
C functions can be declared with a qualifier:
Thread blocs within a grid execute independently.
Any possible interleaving of blocks should be valid
and is presumed to run to completion without pre-emption.
Thread blocks are scheduled on SMs and executed as resources become
available. More than one block may be assigned to an SM but a block may be
assigned to only one SM.
Blocks have indices and threads within a block have indices.
Indices are one dimensional, two dimensional, or three dimensional depending if blocks are 1, 2, or 3
dimensional.
There are built-in variables: threadId [with fields threadid.x, threadid.y, threadid.z],
blockId [with fields blockid.x, blockid.y],
blockDim [specifies the dimensions of a block], gridDim [specifies dimensions of a grid].
When you have concurrency you have synchronization problems.
The function void __syncthreads();
synchronizes all the threads in a thread-block.
Once all threads in a block have reached this point, execution
resumes normally. It is used to deal with race conflicts in use of shared
memory. The execution of storage operations of a thread may be
reordered by
the processors. The call threadfence() can be used to make sure that all
memory operations in a block that precede this call have completed
before this call
completes.
There are atomic operations for variables in global memory (things like
adds, etc., including CompareAndSwap). Semaphores or mutexes are not
provided and are against the spirit of CUDA programming, though they can
be user defined.
As we have seen
cudaThreadSynchronize() is a barrier for threads within a device.
A host program could use multiple devices. Examples of calls used to this end are
cudaGetDeviceCount( int* count ),
cudaSetDevice( int device ),
cudaGetDevice( int *current_device ),
cudaGetDeviceProperties( cudaDeviceProp* prop, int device )
cudaChooseDevice( int *device, cudaDeviceProp* prop ).
One CPU thread can control one GPU
or multiple CPU threads can control that same GPU.
Host calls to the devices are serialized.
At last, how does the host program call device program? with calls of the form
foo<<<GridDim, BlockDim>>>(. . .)
where the funny notation specifies the dimensions of the grid and of the
blocks [ a third optional parameter can be used to specify size of block shared memory].
If two successive calls to grids share some data, then they will be
executed in sequence with implicit synchronization.
Here is a simple program used to sum two square arrays a and b into a third, c. That is c[i] is a[i] + b[i]. In a sequential program this would be done by something like
for (int i = 0; i < N; i++) {c[i] = a[i] + b[i];}
In CUDA the loop is unwound and each assignment done in a different thread since each
will operate on different data.
#include <stdio.h>
#include <assert.h>
// Set grid size
const int N = 1024;
const int blocksize = 16;
dim3 dimBlock( blocksize, blocksize );
dim3 dimGrid( (N + dimBlock.x - 1)/dimBlock.x, (N + dimBlock.y - 1)/dimBlock.y );
// compute kernel
__global__
void add_matrix( float* a, float *b, float *c, int N )
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
int index = i + j*N;
if ( i < N && j < N )
c[index] = a[index] + b[index];
}
int main() {
// CPU memory allocation
const size_t size = N*N*sizeof(float);
float *a = (float *)malloc(size);
float *b = (float *)malloc(size);
float *c = (float *)malloc(size);
// initialize the a and b arrays
for ( int i = 0; i < N*N; ++i ) {
a[i] = 1.0f; b[i] = 3.5f; }
// GPU memory allocation
float *ad, *bd, *cd;
cudaMalloc( (void**)&ad, size );
cudaMalloc( (void**)&bd, size );
cudaMalloc( (void**)&cd, size );
// copy data to GPU
cudaMemcpy( ad, a, size, cudaMemcpyHostToDevice );
cudaMemcpy( bd, b, size, cudaMemcpyHostToDevice );
// execute kernel
add_matrix<<<dimGrid, dimBlock>>>( ad, bd, cd, N );
// block until the device has completed
cudaThreadSynchronize();
// check if kernel execution generated an error
cudaError_t err = cudaGetLastError();
if( cudaSuccess != err) {
fprintf(stderr, "Cuda error: %s: %s.\n", msg, cudaGetErrorString( err) );
exit(-1);
}
// copy result back to CPU
cudaMemcpy( c, cd, size, cudaMemcpyDeviceToHost );
// verify the data returned to the host is correct
int j, k;
for (j = 0; j < numBlocks; j++) {
for (k = 0; k < numThreadsPerBlock; k++) {
assert(c[j * numThreadsPerBlock + k] = 4.5f);
}
}
// clean up and return
cudaFree( ad ); cudaFree( bd ); cudaFree( cd );
free( a ); free( b ); free (c);
return 0;
}
Then store in source file (say, MatrixAdd.cu)
Compile with
nvcc MatrixAdd.cu
Run