Distributed Systems
Distributed systems [i.e. applications and systems that involve intercommunicating software that runs at a number of computer systems] are intended to meet a number of requirements such as:- Openness
- We aim for Universal Service, the ability of any system to interact with any other system. We move towards it making our systems "open", with well defined interfaces, using standard (national/international) protocols. There are languages for specifying interfaces ( IDL: Interface Definition Language, WSDL for specyfying web services). With XML (Extensible Markup Language) we aim to represent and exchange data in tagged and formatted text form. We separate Policy from Mechanism, i.e. what is done from how it is done.
- Scalability
- In the last decade we have seen growth by many orders of magnitude in the number of users of the internet, in the traffic, in the number of nodes. The algorithms and techniques used must remain effective as the scale of the systems grows. "Scalability" is the word used to designate this property of systems, algorithms, techniques, to keep operating well as the scale increases as to number of users, of computer systems, geographic area covered. Clearly an algorithm whose complexity (in terms of messages or of computation) grows like n2, where n is the number of nodes, does not scale well. In fact anything beyond linear growth (which is already bad) is not scalable. [This would be a great time for understanding the rates at which different technologies advance. Things like the rate of speedup in memories, in disk densities, in total internet traffic, in maximum data rate on a data link, ..]
- Reliability
- In a distributed system we have Independent Failures or partial failures, that is parts may fail without the system being fully disabled. We need to detect failures while the system keeps on working. We hope that the system has fault-tolerance, graceful degradation, as our car does when some cylinder stops firing. Redundancy is often used for error detection, for error correction, for error recovery,.. We may require 24x7 uptime, with updates made to the software and to the hardware without having to bring the system off line. System availabilities of 99.999% are not unheard of.
- Transparency
- We hide from users issues of implementation that are not their concern, such as the location of the computer systems [local or remote], whether the system is concurrent, whether data is replicated, whether failures are occurring during service.
- Security
- Issues like Encryption, Authentication, Authorization, Denial of Service, data integrity, data protection, guaranteed service, privacy.
Grid Computing, Computing on Demand, Computing as an Utility
Computing is changing both in the size of problems tackled and in the
organizations and processes through which it is carried out. An example of large
problem is the use of the Large Hadron Collider at CERN that will generate
information about millions of particle collisions per second for distribution to
up to 5000 laboratories around the world, for a total of 15 petabytes of data
annually.
Grid computing
is intended to address such problems that are beyond the reach of any single
supercomputer. In grid computing computation takes place across totally
independent computer systems, each with its own administration and control.
Enormous obstacles in message passing, load balancing, reliability, and
especially
security need to be addressed and solved. Computer systems may participate in a
way totally transparent to their users, taking advantage of unused machine-cycles
and storage. If such obstacles can be overcome, it may become possible to
accomplish the vision of Computing as a Utility or Computing on
Demand that some are suggesting: each user with its local limited equipment
can access reliably and securely as much computing/storage power as it needs at a
each moment, and pay in accordance to use. When/if that happens, goodbye to
traditional data centers.
A typical way in which people organize distributed applications is
represented by the Client-Server Model. In this model
a program at some node acts as a Server which provides
some Service, things like a Name Service, a File Service,
a Data Base Service, etc. The Client sends requests to the Server and receives
replies from it. The Server can be Stateful or
Stateless, i.e. may remember information across different
requests from the same client. The Server can be local, i.e.
on the same system as its clients, or remote, i.e.
accessed over a network.
The Server can be iterative
or concurrent. In the former case it processes one request
at a time, in the latter it can service a number of requests at the same time,
for example by forking a separate process (or creating a separate
thread) to handle each requests. In a concurrent server, the processes
or threads that handle the individual requests are called
slaves (or workers) of the server.
These slaves may be created
"on demand" when a request is received, and deleted when the request
has been handled. Or they may be "preallocated" into a pool of
slaves when the server is started, available to handle future requests.
And the size of this pool can be made adaptive to the load on the
server. [Other servers are called multiplexed;
they are concurrent
without using forks or threads, using instead the "select" function
to respond to multiple connected sockets.]
[Pai in the FLASH web
server, uses a different terminology for concurrent servers. He talks of
Multi-Process (MP) architecture, Multi-Threaded (MT) architecture,
and of Single-Process-Event-Driven (SPED) architecture. He then introduces
a variation of the SPED architecture. This reference is very worth while
for its use of all sorts of clever OS mechanisms for improving
the performance of a server.]
Also the Client could be
iterative or concurrent, depending if
it can make requests to different servers sequentially or concurrently.
Often the interaction from the client to the server is using
Remote Procedure Calls
(RPC), or using Remote
Method Invocation (RMI),
or using CORBA,
SOAP,
web services,...
Note that the way we interact with an object, by calling one of its methods,
is a typical client-server interaction, where the object is the server.
Thus distributed objects fit within the client-server
architecture. An objects, at different times, may play the role of server
or the role of client. In fact an object can act at one time as a server
(responding to a request) and as a client (requesting service from a
third object as part of implementing its own service). [Care
must be taken to avoid loops in server requests: P asks a service from
Q that asks a service from R that asks a service from P. Such loops result
in deadlocks.]
In the Client-Server Architecture the initiative lays with the client.
The server is always there at a known endpoint [usually an IPaddress+port]
waiting for requests, it
only responds to requests [the requests are pulled
from the server as the web server responding to
a browser's request], it never initiates an
interaction with a client
[though in some situation, say for a wire-service, the client may
remain connected to the server and this server will
push content
to the client at regular intervals; also, in email, the mail server pushes
the available mail message to the mail clients, and email clients push
to mail servers new messages].
A Peer-to-Peer Architecture instead emphasizes that the
interaction initiative may lay with any object and all objects may be fairly
equivalent in terms of resources and responsibilities. In the client-server architecture
usually most of the resources and responsibilities lay with the servers.
The clients (if Thin Clients) may just be responsible for
the Presentation Layer to the user and for network communications.
A few more words about Stateful vs Stateless servers.
A stateless server will tend to be more reliable since, if it crashes,
the next interaction will be accepted directly, not rejected , since it is
not part of an interrupted session. Also, the stateless server will require
less resources in the server since no state needs to be preserved across
multiple requests. Hence
the stateless server is both more reliable and more scalable
than a stateful server. A stateful
server, in turn, is usually with higher performance since the state
information can be used to speed up processing of requests.
A further distinction when talking of the "state" of a server, is between
Hard-state and Soft-state. Hard-state
is true state, in the sense that if it is lost because of a crash, we
are lost: the server interaction has to be fully re-initialized. Instead soft-state
if lost it can be reconstructed. In other words, it is a Hint
that improves the performance of a server when it is available. But, if
lost, the state can be recomputed. For example, the NFS server could maintain
for each recent request information on user, cursor position, etc. Then
if another request arrives from that user for that file, this state information
can be used to speed up access. If this 'state" information is lost or becomes stale,
then it can be reconstructed because an NSF request carries all the
information required to satisfy it. Note that a server with soft-state is
really just a stateless server.
The stateful/stateless distinction is used also when talking of
protocols used in the interaction client/server. So we
talk of Stateful or Stateless Protocols.
HTTP, the protocol
used for www interactions, is stateless, since its response to requests are independent of each other,
and so is
the web server.
Also the Network File System (NFS) protocol is stateless.
It deals with accessing files made available by a server on a network.
All requests are made as if no Open file command was available, thus the
requests must explicitly state in the request
the name of the file and the position of the cursor.
Instead the File Transfer Protocol (FTP) is stateful since a session is
established and requests made in context, for example, the current working directory.
Though HTTP is stateless, it can be made stateful by having the clients
preserve state information and sending it to the server at the time
requests are made. This is the role played by cookies.
When the client sends a request, it can provide
the state information (the cookie) with the Cookie header.
When the server responds, it places in the header, with the Set-Cookie
header, the state, appropriately updated [For a dark view of the role
of cookies, see CookieCentral.
Part of the danger is that where normally the cookie is specific to the
interaction between a specific client and a specific server, first-party
cookie, (as when I fetch a page form a specific location, say moo)
it is also possible to have third-party cookies,
that is cookies that collect information across multiple servers and give
it to a hidden server. (For example, the page i fetch from moo may hide a request to a one-pixel
image that is fetched from the third-party.)].
The fact that the state is kept in the client makes the server more scalable
since no space has to be devoted to the clients's state.
Also, if the server crashes,
then the client's state is not affected. For a technical discussion
of cookies and their use in state management
see rfc2109 (in particular,
examine the two examples of client-server interaction).
Remember, cookies are manipulated at the server but stored at the client.
When servers require the power of many computer systems
two architectures are common.
Middleware
Distributed systems are developed on top of existing
networking and operating systems software.
They are not
easy to build and maintain. To simplify their development and maintenance
a new layer of software, called Middleware, is being developed,
following agreed standards and protocols,
to provide standard services such as naming (association of entities
and identifiers, directory services (maintaining
the association of attributes to entities),
persistence,
concurrency control, event distribution,
authorization,
security. Examples of such services
that you may be familiar with are the Distributed Name Service (DNS) with
associated protocol,
the Internet Network Time service with the Network Time Protocol (NTP),
transaction servers, etc.
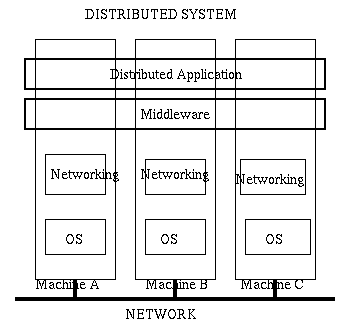
The following diagram indicates the architecture of distributed systems.
Notice that the box we have called networking is itself decomposed
into layers as we will see when we discuss networking issues.
Client-Server Architecture
We receive snail mail thanks to the post office service.
But to us the service is provided by a specific mailman,
a server. As users, our interest is in services,
to identify what services are available and where are the servers
that support each service. So usually we need an "Identification/Discovery
or Naming Service"
that will provide us with the identities of the available services, their properties, and
their servers [and we need to know at least one server of the
"identification/discovery service"]. The problem of characterizing services, in terms of
who they are, what they do, and where they are accessible is of great
current interest. A number of efforts address this problem.
[Here is
a list of advanced activities in this area. Two more
traditional approaches to the problem are UDDI,
WSDL.
Directory/naming services, such as
LDAP,
often are at the basis of identification/discovery services.]
As Google helps people identify resources, these services will allow programs to
do the same.
In this section we discuss various aspects of
servers and their implementation in Unix.
Various aspects of the client server architecture are discussed in the
Tanenbaum-VanSteen pages 42-52, 142-152, 648-668.
One architecture uses vertical distribution, arranging
computers on a number of tiers, usually three. This is the
3-tier architecture: The tier where user interactions take place,
the presentation tier; The tier where user requests are received
and analysed, the application tier; The tier where data
is preseved and manipulated, the data tier. Upon receiving a user
request appropriate interactions take place between the application tier
and the data tier. They result in the development within the
application tier of the response to be sent to the presentation tier.
[As an example the user at the presentation tier may request the best fare
for a trip from a specified location to another within a range of dates.
The application tier will do the leg work of anayzing data base information
and give the answer to the presentation tier. This functionality of the
application tier has been tapped for the direct user use. In general it
would be nice to make that same functionality available as a web
service to generic programs. That requires all sorts of standards and
protocols to describe the service made available and how to request
such service (and who has the right to do so).]
The other architecture uses horizontal distribution between a number
of equivalent, fully functional servers. User requests are routed,
usually in round-robin fashion or hashed on the basis of the requesting IP address,
to one of the available servers. This
architecture is often used by heavily loaded web servers.
Peer-to-Peer Architecture
Let's start with two examples of peer-to-peer (P2P) systems.
Napster is a system
for sharing files, usually audio files, between different systems. These
systems are peers of each other in that any of them may request a file
hosted by another system. The system has a central service used for
the discovery of desired files, i.e. for helping a peer identify peers
where are available desired files.
Instant Messaging is the capability of a system to send a message
to another currently running system. Again a central service may be used to
determine which systems are currently present as potential targets for delivery
of an instant message.
Notice that in both cases we have systems, peers, that have all similar
capabilities and can provide services to, or interact with, each other.
And we have a central service that helps the peers find each other.
This central element [which is available in the form of traditional
server] improves the performance of the system as a whole,
but it is not strictly necessary since the peers could find each other through
a search started from neighbors and propagated as an oil spot
(Gnutella,
Freenet, and
BitTorrent
for instance do not require a central service).
Now we have a general idea of what are peer-to-peer systems. They seem to use two basic ideas: a service to determine which user agents [this means any entity intended to be able to exchange messages] are currently online = a presence service; and a service for delivering immediately a message to a currently active user agent = an instant message service.
An interesting P2P system is BitTorrent. Now we are
interested in downloading a movie from a server without overwhelming the
server when multiple clients are downloading the same movie. So the movie
is divided in segments and the clients become servers themselves for the
segments they have downloaded.
Interactions
We have seen two important distictions on the interactions taking place
between two interacting systems
Here some other important distinctions
Finally for interaction there is a famous Robustness
Principle enunciated by Jon
Postel: "Be liberal in what you accept, and
conservative in what you send." , that is, follow all the rules
when sending out information, and when you receive it, try to understand
it even if the sender did not follow all the rules.