Transactions II
[This topic is presented in pages 150-154 in Tannenbaum.]
We have talked of the desired properties of transactions using the
ACID acronym:
- Atomicity: All or none behavior.
- Consistency: Each transaction is correct, that is, it
preserves the invariants of the system (things like "the sum of all
credits and debits is zero").
- Isolation: Intermediate results during execution are invisible.
This is like saying that the
effect of the concurrent execution of transactions
is equivalent to their serial execution (thus, also called Serializability).
- Durability: the effect of a transaction that completes successfully
(commits) is persistent.
Durability is taken care by saving results in persistent storage.
Consistency is taken care at the application, not at the tool level
[my money transfer transaction should worry about preserving accounting
rules].
Isolation is taken care with two-phase locking [or with timestamps].
We are left with a fundamental problem: atomicity. We need to
examine how to deal with failure, aborts, commits.
Atomic transactions on a single system
We consider first the case where a single computer is
involved in a transaction. Usually the data is maintaned in a database
(we could also have flat files) under the control of a database manager (DM)
(in this context it is often called just resource manager).
Since reading from disk is slow and since synchronous writes to
disk are very slow, all sorts of buffering schemes and caches are used.
Thus write operations to persistent storage
will have to be done in the correct order and,
unless one is careful, data will be lost in case of system crashes.
A number of implementation strategies are possible.
- WriteAhead Log - Redo-Only, also called Deferred-Update
We assume we have in stable storage a writeahead log (also called a
Redo Log, or a Database Log, or an Intentions List), it is just a sequential
file.
Initially all the operations are done without modifying the data base,
just writing to the log for each update command the command and
the data that has to be written to complete the operation.
When all this information has been logged (this phase is called
the precommit phase) a commit record is written to the log.
Anything of the transaction that was done before this commit, in the case of
failure, is lost and we are as if back to the beginning of the
transaction. After the commit, the transaction will be completed
on the real data, not the log, because
we have in the log all the information needed to carry it out.
This method of implementing
the transaction is called redo-only because when we
commit we need to redo each (update) operation of
the transaction (if we give up we need not do anything
to the database).
The order in which log records are written is important since they must
be done over in the same order (at least, conflicting operations
must be done in the same order as indicated in the log) in the redo phase.
Here is what is done in correspondence to
the various operations of a transaction:
- StartTransaction: Write e new transaction record to the WriteAhead Log.
- Write (or Update): Write a Redo Record to the Redo Log. This record
contains the id of the transaction,
the identity of the variable being updated and the value being written.
- Read: Now we need to check if the variable to be read has already
been updated in the transaction,
thus we have to combine the information in the Redo Log with what is in the
database or, better, we can keep the updated object in the cache until the
transaction is committed and the new value written to persistent memory.
- Abort: discard the Redo Log of this transaction (and the updatedS objects
from the cache).
- EndTransaction (Commit): After all log writesare completed,
write to log the commit record and
apply to the database in order the actions in the WriteAhead
Log, from oldest to newest.
- WriteAhead Log - Undo-Only, also called Update-in-Place
An alternative is
to have a precommit phase where for each update command
we save to the WriteAhead Log (also called an Undo Log) the data that will
be modified (so that we can undo the command) and we
execute on the real database the command. We then
write a commit record to the log. If there is a crash
before the transaction is completed, we rollback the old values
by reading them from the
log from last to first. This method of implementing the transaction is called undo-only
since in case of failure before the commit we need to undo all the
updates done to the database.
Here is what is done in correspondence to
the various operations of a transaction:
- StartTransaction: Write a new transaction record to the Undo Log.
- Write (or Update): Write an Undo Record to the Undo Log. This record
contains the id of the transaction, the identity of the variable being updated and its old value. Then write the
new value to the data base. The Undo Record (at least, the old value)
must be in disk before the new
value is written to the DB.
- Read: Just read the value from the data base.
- Abort: Carry out the undo operations in reverse order to the one they were
done in.
- EndTransaction (Commit): Write to disk a commit record for the
transaction. Then discard the undo log for the transaction. The commit record cannot
be written until the old values of all objects modified in the transaction have
been written to disk.
- Private Workspace
This is an interesting idea already encountered in Copy-On-Write (COW)
fork operations and in Write-Once file systems. The idea is to
give to each user its own copy of the data being updated, but this
copy is just a directory of the blocks affected (the blocks may come from
many files). Then when the update is made by a transaction to a block, it is written to a new
block (called a shadow block) and the directory of that transaction is updated to point
to this new block. When all updates are carried out and the new directory
is copied to a log in stable storage
together with a commit record, the transaction is
ready to be completed by updating atomically the real directories of the
database. Notice that in case of failure before commit we do not
need to do anything to the database, just update lists of free blocks since blocks allocated
to the aborted transactions can be recovered.
All logs are kept in stable storage. For each transaction we will have
a start transaction record and an end transaction record. Then space for
the log can be recovered by compaction after freeing the space associated
to completed transactions, or by treating the log as a circular tape
where we restart from the beginning after having reached the end.
Restart is the operation required after a system failure.
The restart operation will take care of the transactions that were not completely
done at the time of the crash. Aborted transactions are undone, committed
transactions are completed, and uncommitted transactions are restarted.
Checkpoints (i.e. the saving of intermediate values of objects
during a transaction) can be used to reduce the amount of work to be done
during restart.
Atomic Transactions in a Distributed System
The problem is the following: A number of systems are involved
in executing a transaction. One is the transaction manager or coordinator,
say it is system 1,
the system where the transaction was started.
All other systems have a resource manager that operates as indicated above
for transactions on single systems. A resource manager
is responsible
for carrying out the local operations keeping a local log
and, in addition, for communicating with the (transaction) manager.
Each system has available stable storage to record
reliably their progress and decisions across temporary
local failures and recoveries.
We assume that communication is reliable and we accept the fact
that any system may fail and recover. We want to reach the situation where
all systems complete in agreement that the transaction is
committed (and they all are in the new state) or that it is
aborted (and they all are in the old state). Of course
the agreement should be faithful to the truth: there
is commitment iff all systems will complete their tasks.
A solution is provided by the Two-Phase Commit Protocol.
Part 1:
The transaction(a program in the transaction) starts by informing
the transaction manager (or coordinator) that will write to
stable storage a StartTransaction record and inform all participant
resource managers (also called participants).
Now the transaction is Active.
Carry out the operations of the transaction at each system
as we did in the pre-commit phase in the single system transaction.
Agreement Protocol:
At this point all the operations of the transaction have been
carried out in a "non-committed" fashion. A program in the transaction
issues the "commit" request (only one program can do that).
The manager writes a pre-commit record to the log (stable storage)
and sends to all participating resource managers the request that
they report their decision to commit or abort (REQUEST-TO-PREPARE):
Round 1:
All participants write a pre-commit or abort record to
the log (stable storage) and report to the coordinator
their local decision to commit or abort. A participant
will send a commit reply (PREPARED) only if it has saved to stable
storage all its state and the pre-commit record. Otherwise
it replies NO.
The coordinator collects the answers [if any is late, it
assumed to be an abort] then decides to commit iff
all replies were to commit. The decision is recorded
in stable storage at the coordinator with a commit record
Round 2:
The coordinator informs all participants of the decision with
a COMMIT or ABORT message. Now the participants must
carry out that decision. [The coordinator
will keep sending the decision until it
is recorded in stable storage at all participants.]
A participant will acknowledge with a DONE message a received commit
message so that the coordinator can stop overseeing this
participant and release resources it may be holding.
Part 2:
The actions are finalized at all systems. This can be accomplished
reliably since what to do is recorder in stable storage
at each site. The transaction becomes Inactive.
Note that people think of the two phases as referring to Part 1 and
Part 2, while in reality the two phases refer to the two rounds of
the agreement protocol.
The agreement protocol requires 3(n-1) messages [4(n-1) if we count
the REQUEST-TO-PREPARE message],
where n is the number of systems.
A transaction can be in one of four states:
- Executing: From the start of the transaction to the start of the two-phase
protocol.
- Uncertain: During the two-phase protocol.
- Committed or aborted: After the two-phase commit protocol before the
completion of the transaction.
The following two pictures display respectively the interactions between
the coordinator and a participant during a transaction,
and what they do in the case of failures.
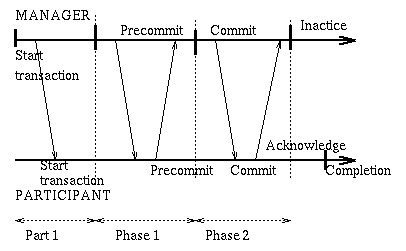
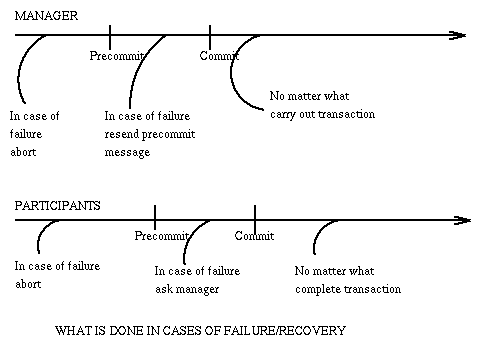
The two-phase commit protocol is imperfect since
it assumes that no system will fail permanently.
- Consider the case that a participant
j fails permanently after round 1 when all had agreed to commit.
Then the coordinator decides to commit and informs the others in Part 2
but the transaction cannot complete since system j is not there to
accept the message from the coordinator and acknowledge it,
and the coordinator cannot abort because
by now some systems may have finalized their action.
The transaction remains in the uncertain state and becomes blocked.
Some extraordinary action must be taken, usually in the form
of a compensating transaction that undoes or somehow fixes
the previous transaction.
- It is also a problem if
the coordinator fails permanently at the end of round one, just before
recording its decision. The participants that have failed will know what to do
[abort, thus re-establishing the previous state],
but those that had decided to commit are in trouble [they are left hanging
on how to finalize the transaction, i.e. they are blocked] and the
transaction remains in the uncertain state. These blocked systems will attempt
to reach resolution by sending queries to the coordinator requesting
disposition information for the incomplete transaction.
So some additional work, not part of the two-phase commit
protocol, needs to be done to handle these problems.
Basically, we need to have some way of knowing when we can close the
books on a transaction and say that it is done.
A three-phase commit protocol has been suggested to deal
with the weaknesses of the two-phase protocol.
Impossibility of Guarantieing Consensus in Asynchronous Systems
The problems enclountered in the Two-Phase Commit Protocol (the blocking
of the transaction) is an example of a general problem: our inability
to guarantee arriving at a consensus in a system where
- messages are reliable,
- the execution and communication times of systems are not
with known upper bounds
- one system may fail.
Because of this impossibility, one aims not to guaranty consensus, but to
minimize the probability of failing of achieving consensus. Also, one
aims to establish
emergency procedures for handling failures.