 CIS 307: Introduction to Distributed Systems II
CIS 307: Introduction to Distributed Systems II CIS 307: Introduction to Distributed Systems II
CIS 307: Introduction to Distributed Systems II
In discussing algorithms in a distributed environment we can distinguish 2+1 cases:
The -> relation is a partial order. Given events e1 and e2 it is not true that either they are the same or one happened-before the other. Events that are not ordered by happened-before are said to be concurrent.
This characterization of happened-before is unsatisfactory since, given two events, it is not immediate (think of the time it takes to evaluate a transitive relation) to determine if one happened before the other or if they are concurrent. We could like a clock C that applied to an event returns a number so that the following holds:
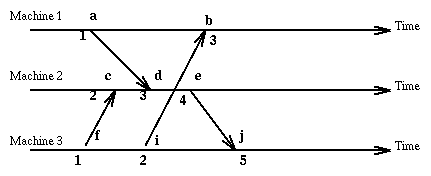
Since the method we have chosen allows different events (on different machines) to have the same logical clock value, we extent the clock value with a number representing the machine where the event occurred [i, C(e)] and order these pairs according to the rule:
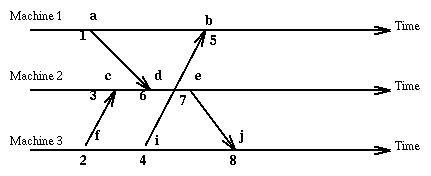
Here is our old example using vector clock values.
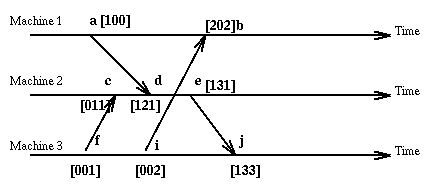
Of course nothing is perfect. So the use of vector clocks results in big time stamps and requires that we know in advance the identities of the sites involved.
I am on a computer system and I want to transfer $100 to your account. So I reduce my account by $100 and send you a message announcing the deposit. When you receive the message, you increment your balance. But during the time the message is in transit by looking simultaneously to your account and my account we find that they are painting the wrong picture. That is, the states that are visible in the two different systems should be as if no message were ever in transit. [Another way of saying this would be to say that the withdrawal/deposit should form an atomic transaction.] If we call local state the content of variables at a site (i.e. its state), global state a vector with as components the local states in the distributed system being considered, and consistency between two distinct local states the fact that the corresponding sites do not have messages in transit, then a consistent global state is one whose component local states are pairwise consistent. For many applications it would be desireable to do things so that the global state is consistent. Equally desireable is to be able to record successive consistent global states (think of debugging).
Here is how a client would operate
..........
Send request to M
Wait for reply from M
Use resource R
Send release notice to M
..........
This means that each use of the resource will have as overhead 3 messages.
If W is the time we use the resource and T is the time taken by each message
then the total time spent for a critical region is (W+3T) and the maximum
rate of use of the resource is 1/(W+3T). Of course W/(W+3T) is the maximum
utilization possible for the resource.
Now we look at what is done by the manager M:
It uses two variables:
resourceIsFree, a boolean indicating state of resource, initially true;
rqueue, a FIFO queue containing pending requests;
loop {
wait for a message;
if the message is a request {
if resourceIsFree {
allocate resource to requestor;
set resourceIsFree to false;
} else
insert request in rqueue;
} else /* it is a release */
if rqueue is empty
set resourceIsFree to true;
else {
remove a request from rqueue;
send reply to that requestor;}
}
Of course we are in trouble if the Manager dies. Firstly we do not
know its current state (i.e., the state of the resource and who
is waiting), second, we don't have a coordinator anymore. For the second
problem we hold an election to select new manager. For the first problem,
each process has to recognise failure and adjust accordingly [each process
knows its own state and can communicate it to the new manager].
self: the identity of this process (a number like 7);
localClock: an integer representing a local logical clock (initially 0);
highestClock: an integer, the largest clock value seen in a request
(initially 0);
need: an integer representing number of replies needed before self
can enter the critical region;
pending: a boolean array with n entries; entry k (k!=self) is true
iff process Pk has made a request and process self has not responded;
the self entry is true if process self wants to enter critical region;
s: a blocking semaphore used to hold the processing thread while the
comunication thread takes care of synchronization.
loop {
wait for a message;
if the message is a request {
let k be the identity of requestor and c the clock on message;
set highestClock to max(highestClock, c);
if (pending[self] and ([self,localClock] < [k, c]))
set pending[k] to true;
else
send response to k;
} else { /* the message is a reply */
decrement need by 1;
if need is 0
V(s);}
}
set pending[self] to true;
set localClock to highestClock + 1;
set need to n-1;
send to all other processes a request stamped with [self, localClock];
P(s);
CRITICAL REGION
set pending[self] to false;
for k from 1 to n {
if pending[k] {
send response to k;
set pending[k] to false;}
This algorithm, due to Ricart-Agrawala has been extended by Raymond to the
case where more that 1 process can be in the critical region at one time and
to the case where requests are for multiple copies of a resource.
In the case that we do not have a ring communication topology, we can still accomplish achieve mutual exclusion using the concept of token. The algorithm is due to Chandy.
We have n processes P1, .., Pn. The token contains a vector [T1,..,Tn] where Ti is the number of times that process Pi has been in the critical region. Each process Pi has the variables:
loop {
wait for a message;
P(mutex);
if (withToken is true){
if (clock on stamp is not less than on token) {
send token to requestor;
set withToken to false;}
/* else the message is discarded */
} else {
insert it into rqueue;}
V(mutex);
}
.................
send request time stamped [i,mi] to all other processes;
wait for token;
CRITICAL REGION
set mi in token to mi+1;
set Ti to mi;
P(mutex);
while rqueue is not empty {
dequeue a request, say, time stamped [j, mj];
if mj < Tj {
it is a stale request; throw it away;
} else {
send toKen to Pj;
}
if token was not sent out
set withToken to true;
V(mutex);
.................
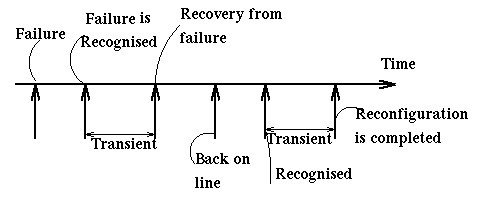
The following figure shows the time relations between the time of failure, the time the failure is recognized, and the time when the system has reconfigured itself to deal with the failure. The time between the recognition of failure and the completion of reconfiguration is a transient. We have a transient also when a node comes back on line and the system has to reconfigure itself. Things can get exciting (i.e. dangerous) when the two transients overlap.
We can reason as follows with generals A and B. A sends a message to B suggesting "attack at 7am". When A receives agreement from B, it attacks at 7am. The problem is, how does B know that A has received agreement? he cannot thus he does not attack at 7am. So may be A on receiving agreement from B it sends an acknowledgement to B. But then A will not know if B has received the acknowledgement and it will not attack at 7am. There is no solution with a finite sequence of messages. If there were, the last general to send a message would not know if the other general has received that message. Thus that last message cannot be necessary for the agreement, thus the sequence was not minimal. Contradiction. Loyal generals, in the case of unreliable communication cannot reach absolute certainty on when to attack.
ingargiola.cis.temple.edu