Transactions are easy to use. A Transaction Server will support operations to Start a Transaction and to End a Transaction. The termination of a transaction can take two forms: success, called commit, and failure, called abort. Abort gives up on the current transaction. Many are the reasons for aborting a transaction. They range from the internal logic of the transaction (like making reservations for a multi leg trip and then giving up in the middle when a particular leg cannot be scheduled) to crashes occurring in one of the systems taking part in a distributed transaction. When a transaction commits or aborts, many house-keeping action will be required to complete ("close the books" on) the transaction. The Transaction Server will worry about how to guaranty transactionality for the actions performed between the Start and End delimiters. It is a "service" provided to us without need for us to program anything: it is both valuable and free.
The concept "transaction" is fundamental in our discipline. It takes a number of operations and executes them atomically, without any worry about potential concurrent activities. As the systems of the future will have a multitude of processors and people confront the fact that concurrent programming with threads and locks is hard and error prone, alternatives are sought. Transactions offer an alternative way of dealing with concurrency. Already people have been working on Software Transactional Memory [STM]. It is likely to be influential in the future.
We have from the beginning of the course worried about the concurrent execution of activities, their possible interleavings (or schedules), about mutual exclusion, and critical sections. Here we examine a number of undesirable behaviors caused by interleavings that violate the ACID properties. These interleavings lead to transaction aborts.
A1: Read value of Account 1
A2: Add 100 Dollars to it
B1: Read value of Account 1
B2: Add 1000 Dollars to it
B3: Store value in Account 1
A3: Store value in Account 1
This interleaving results in a balance of 1100 dollars and not 2100 dollars
as it should be.
A1: Read value of Account 1
A2: Subtract 100 dollars from it
A3: Store value in Account 1
B1: Read value of Account 1
B2: Print this value
B3: Read value of Account 2
B4: Print this value
A4: Read value of Account 2
A5: Add 100 dollars to it
A6: Store value in Account 2
This interleaving will result in the apparent disappearence of 100 dollars.
A0: Start
A1: Read value of Account 1 (say 100)
A2: Add 10 to it
A3: Store value in Account 1
B0: Start
B1: Read value of Account 1
B2: Add 5 to it
B3: Store value in Account 1
B4: End
A4: Abort
The problem in this interleaving is that B uses a value updated by a
transaction that has not yet been committed. This situation should never
occur, since B is committed, yet it should be aborted because it uses
the results of the aborted A transaction. This is a form of cascaded
abort.
A0: Start A1: Read value of Account 1 (say 100) A2: Add 10 to it B0: Start B1: Read value of Account 1 A3: Store value in Account 1 B2: Add 5 to it B3: Store value in Account 1 B4: Abort A4: EndThe problem in this interleaving is that when the B transaction aborts, it re-establishes the initial value of the account, thus wiping out the effect of the A transaction. Thus, if we get in trouble as in the Dirty Read and Premature Writes, we need to abort also the other transaction (B in Dirty Read, A in Premature Writes). This is again a form of cascading aborts.
If transactions are executed one after the other [this is called a serial schedule], we avoid the aberrations that are caused by their concurrent execution on shared data. But by doing so the response time in executing the transactions becomes excessive, more than users will tolerate. Fortunately not all is lost: to avoid aberrations it is not necessary to have serial schedules, serializable schedules will suffice: a serializable schedule is a schedule that is equivalent to a serial schedule on the basis of the Bernstein's Conditions. This requires some thought and explanation.
Let's use the notation W(a) to indicate a write operation on object a and R(b) to indicate a read operation on object b. Let S be the start of a transaction, A is the Abort, and C is the Commit. In describing transaction Ti, let's append an i to its S, A, C, R and W operations, say, Si, Ai, Ci, Wi(a), and Ri(b). For the time being let's postpone consideration of S, C, and A operations, focusing only on R and W. Two operations that operate on the same object are said to be conflicting operations if they are not both read operations. This reflects what we know from the Bernstein's conditions. Conflicting operations cannot be reordered.
Now let's consider some transactions:
T1: R1(a) R1(b) W1(a) T2: R2(b) R2(a) W2(b)and the schedule ("schedule" is another name for "interleaving")H1:
H1: R1(a) R1(b) R2(b) W1(a) R2(a) W2(b)[For the time being we do not worry about locking any item.] Since R2(b) and W1(a) operate on different objects, their order could be changed without affecting the result when executing H1. Thus we would get the schedule H2:
H2: R1(a) R1(b) W1(a) R2(b) R2(a) W2(b)which is just the serial execution of T1 followed by T2. In this case we say that the schedule H1 is serializable. Of course not all schedules are serializable. For example the schedule H3:
H3: R1(a) R1(b) R2(b) R2(a) W1(a) W2(b)is not serializable since R2(a)W1(a) cannot be reordered as W1(a)R2(a) since the values for a used in T2 in the two cases are different. [This is basically what was said with the Bernstein's conditions.] And also R1(b)W2(b) cannot be reordered for the same reason.
We have a general way to determine if a schedule is serializable. Suppose that we have a schedule of transactions T1, T2, .., Tn. We create a serialization graph with nodes T1, T2, .., Tn. We then put an arc from node Ti to node Tj (and we say Ti precedes Tj) if we find in the schedule an Ri(x) before a Wj(x) or a Wi(x) before an Rj(x) or a Wj(x). Notice that these operations will have to be protected by read or write locks and Ti will have to release the lock on x before Tj can acquire the lock on x. [Our discussion of conflicting operations and serializability, is a simplification of reality. The order of read and write operations on the same object by different transactions has to be preserved - for example R1(x)..W2(x) must be kept in this order as does W1(x)..R2(x). But when considering write operations to one object without intervening reads, only the last write matters. For example,W1(x)W2(x)W1(x) is equivalent to W2(x)W1(x)W1(x) since the effect of these operations depends only on the last W1(x).]
Serializability Theorem: A schedule is serializable if and only if its serialization graph is acyclic.
But this theorem is not easy to apply: it is not reasonable to expect that transactions will be executed while checking at all times that no loop occurs in their serialization graph.
We will say that a transaction follows a Two-phase Locking [2PL] Policy if it never applies a lock after having released a lock. The first phase is when we apply locks, the second phase is when we release them.
Theorem: If transactions follow the two-phase locking policy then schedules that respect the locks and don't deadlock, are serializable. Viceversa schedules that are not serializable will deadlock.
We examine only the case of two transactions, T1 and T2 that have conflicting operations on objects a and b. Without loss of generality we can assume that the first operation is by T1 on a. We have cases
1. a1 b1 // then a2 and b2 in some order - serializable with no deadlock 2. a1 a2 // then T2 will block until T1 is done - serializable with no deadlock 3. a1 b2 // now no matter the order of a2 and b1, - non serializable, with deadlock
Two problems remain when using two-phase locking:
T1: L1(x) W1(x) L1(y) W1(y) U1(x) U1(y) T2: L2(y) W2(y) L2(x) W2(x) U2(y) U2(x)we can create the schedule
L1(x) W1(x) L2(y) W2(y) L1(y) L2(x) ...that is two-phase locking and results in deadlock when T1 executes L1(y) and T2 executes L2(x).
T1: S1 L1(x) W1(x) U1(x) A1 T2: S2 L2(x) R2(x) W2(x) U2(x) ..the two-phase locking policy will allow the schedule
S1 L1(x) S2 W1(x) U1(x) L2(x) R2(x) W2(x) U2(x) A1 ..which will require a cascaded abort A2 after T1 aborts.
Cascading aborts can be fully prevented if a transaction does not release any write lock until the transaction is completed (committed or aborted: strict 2-phase locking [S2PL]). This is a policy that results in decreased concurrency and increased delays. Yet the complication of having to deal with cascading aborts is such that strict scheduling is usually adopted. In these notes, unless otherwise indicated, we will assume strict scheduling.
Lock management is usually not a programmer's concern. Locks can be inserted automatically by the system to enforce a desired policy. For example, if we have transaction T:
S R(x) R(y) W(x) W(y) R(z) W(u) C then locks can be inserted as follows [using 2PL]: S L(x) R(x) L(y) R(y) W(x) L(z) L(u) U(x) W(y) U(y) R(z) U(z) W(u) U(u) C or, better, [using S2PL]: S L(x) R(x) L(y) R(y) W(x) W(y) L(z) R(z) L(u) W(u) C U(z) U(x) U(y) U(u)
The use of timestamps to serialize transactions can be refined.
Assume that to each object X we
associate two timestamps.
W-timestamp WTS(X) is the start timestamp of the transaction that
wrote last successfully to X. Similarly R-timestamp RTS(X) is the latest start
timestamp among the transactions that have read successfully from X.
When transaction T wants to read from X, if ST(T) is less than
WST(X), T is aborted. Otherwise it succeeds and RTS(X) is set to the largest
of RTS(X) and ST(T).
When transaction T wants to write to X, if ST(T) is less than the RTS(X)
or less than the WTS(X), T is aborted. Otherwise it succeeds, the write is executed and the
WTS(X) is set to the start timestamp of T.
Notice that the timestamps on an object X are monotonically increasing.
For example, the refinement in the use of timestamps allows the following interleaving to complete
successfully, which would not have been possible with the simple use of timestamp introduced
earlier [transaction 1 would have aborted at 4]:
Transaction 1 Transaction 2 R-timestamp W-timestamp 1 Start 0 0 2 Start 3 read X 2 4 read X 2 5 write X 2 6 write Y 1 (of Y) 7 Commit 8 Commit
A number of implementation strategies are possible. Among them:
variable newValue ================== x 6 y 7 x 8 z 9 y 10 w 11Now we commit the transaction. Then in order, while the locks are being held, we write in the database 11 to w, 10 to y, 9 to z, and 8 to x. The older writes to x and y are not done since we have already updated these variables with more recent values. Then the locks are released, the transaction is completed (becomes inactive) and a transaction completed record is written to the log. Notice that in the commit phase we only do write operations and that the order in which we do them within a transaction is immaterial (the writes are all to distinct objects). Thus scheduling of these operations can be done so as to improve efficiency.
variable oldValue newValue ================================ x 1 6 y 2 7 x 6 8 z 3 9 y 7 10 w 4 11
Checkpoints (i.e. the saving of intermediate values of objects during a transaction) can be used to reduce the amount of work to be done during restart for undo-only logging. Checkpointing consists of three phases:
Part 1:
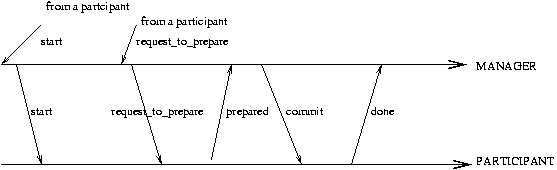
The transaction(a program in the transaction) starts by informing
the transaction manager (or coordinator) that will write to
stable storage a StartTransaction record and inform all participant
resource managers (also called participants).
Now the transaction is Active and all participants are in the
working state.
Carry out the operations of the transaction at each system
as we did in the pre-commit phase in the single system transaction.
[We are holding locks.]
Agreement Protocol:
At this point all the operations of the transaction have been
carried out in a "non-committed" fashion holding locks. A program in
the transaction issues the "REQUEST_TO_PREPARE" request to the transaction manager.
Phase 1:
The manager writes a pre-commit record to the log (stable storage)
and sends to all participating resource managers the request that
they report their decision to commit or abort (REQUEST-TO-PREPARE).
A resource manager that receives this request moves
into the prepared state.
The resource manager writes a pre-commit or abort record to
the log (stable storage) and reports to the coordinator
its local decision to commit (PREPARED message) or abort
(NO message).
The coordinator collects the answers [if any is late, it is
assumed to be an abort] then decides to commit iff
all replies were to commit. The decision is recorded
in stable storage at the coordinator with a commit record
At this point, if commit was chosen, the transaction is
"committed": it must be brought to a successful conclusion.
Phase 2:
The coordinator informs all participants of the decision with
a COMMIT or ABORT message.
Now the participants must
carry out that decision.
[The coordinator
will send at intervals the decision until it
receives a DONE message from all participants.]
When a participant receives the commit message, it transits to the
committed state.
A participant will acknowledge with a DONE message a received commit
or abort message so that the coordinator can stop overseeing this
participant and release resources it may be holding.
Part 2:
The actions are finalized at all systems. This can be accomplished
reliably since what to do is recorder in stable storage
at each site. The participant record the completion of the
transaction in their log and the transaction becomes Inactive.
Note that people think of the two phases as referring to Part 1 and
Part 2, while in reality the two phases refer to the two rounds of
the agreement protocol.
The agreement protocol requires 4(n-1) messages,
where n is the number of systems.
Notice that the transaction manager has to write to stable storage during the transaction
the starttransaction information, then the prepared message, then either the committed or
aborted message (at a later time it can write that the transaction is inactive). Thus 3
synchronous writes are required, i.e a transaction will take more than 10 milliseconds to
complete, independently of any communication delays.
The transaction is active when in any state but the inactive state.
The two-phase commit protocol is imperfect since it assumes that no system will fail permanently.
A0: Start A1: Something A2: Start A3: Something A4: Abort A5: Start A6: Something A7: End A8: Something A9: End is equivalent to just A0, A1, A5, A6, A7, A8, A9.