CIS 5516: Principles of Data Management - Spring 2023
Assignment 4
NOTES:- 10% penalty for each day late, up to three days.
- This is an individual homework; no groups allowed.
This assignment is meant to give you practice with foundations of database systems: Query Evaluation and External Sorting.
Problem 1: (Hashing)
Consider the Linear Hashing index shown in the figure below. Answer the following questions about this index: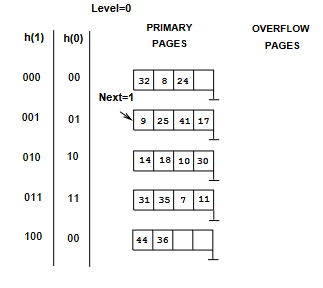
- Suppose you know that there have been no deletions from this index so far. What can you say about the last entry whose insertion into the index caused a split?
- Show the index after inserting an entry with hash value 4.
- Show the original index after inserting entries with hash value 15.
Problem 2: (Indexing)
Consider the following relations: Emp(eid: integer, ename: varchar, sal: integer, age: integer, did: integer) Dept(did: integer, budget: integer, floor: integer, mgr_eid: integer) Salaries range from $10,000 to $100,000, ages vary from 20 to 80, each department has about 5 employees on average, there are 10 floors, and budgets vary from $10,000 to $1M. You can assume uniform distribution. For each of the following queries, which of the listed index choices would you choose to speed up the query? Explain briefly (no more than 3 lines).- Query 1: Print ename, age, and sal for all employees.
- Primary (clustered) hash index on (ename, age, sal) fields of Emp.
- Secondary (unclustered) hash index on (ename, age, sal) fields of Emp.
- Primary B+ tree index on (ename, age, sal) fields of Emp
- Secondary hash index on (eid, did) fields of Emp.
- No index.
- Query 2: Find the dids of departments that are on the 10th floor and have a budget of less than $15,000.
- Primary index on the floor field of Dept.
- Secondary index on the floor field of Dept.
- Primary B+ tree index on (floor, budget) fields of Dept.
- Secondary B+ tree index on (floor, budget) fields of Dept.
- No index.
Problem 3: Files
Consider a disk with a sector size of 512 bytes, 2,000 tracks per surface, 50 sectors per track, five double-sided platters, and average seek time of 10 msec, the disk platters rotate at 5,400 rpm (revolutions per minute). Suppose that a block size of 1,024 bytes is chosen. Suppose that a file F containing 100,000 records of 100 bytes each is to be stored on such a disk and no record is allowed to span two blocks.- How many records fit onto a block?
- How many blocks are required to store the entire file F?
- How many records of 100 bytes each can be stored using this disk?
- What time is required to read the file F sequentially?
- What time is required to read the file F randomly?
Problem 4: External Sorting
Answer the following questions for each of these scenarios, assuming that our most general external sorting algorithm is used:- A file with 100,000 pages and 30 available buffer pages.
- A file with 200,000 pages and 50 available buffer pages.
- A file with 20,000,000 pages and 170 available buffer pages.
- How many runs will you produce in the first pass?
- How many passes will it take to sort the file completely?
- What is the total I/O cost of sorting the file?
- How many buffer pages do you need to sort the file completely in just two passes?
Problem 5: Query Evaluation
Consider the join between relations R and S, where the join condition is R.a = S.b. We are given the following information about the two relations. The cost metric is the number of page I/Os, and the cost of writing out the result should be uniformly ignored.- Relation R contains 10,000 tuples and has 10 tuples per page.
- Relation S contains 2,000 tuples and also has 10 tuples per page.
- Attribute b of relation S is the primary key for S.
- Both relations are stored as simple heap files.
- Neither relation has any indexes built on it.
- 52 buffer pages are available.
- What is the cost of joining R and S using a simple nested loops join?
- What is the cost of joining R and S using a block nested loops join?
- What is the cost of joining R and S using a sort-merge join?
- What is the cost of joining R and S using a hash join?
- How many tuples will the join of R and S produce, at most, and how many pages would be required to store the result of the join back on disk?
- If secondary B+ indexes existed on R.a and S.b, would either provide a cheaper alternative for performing the join (using an index nested loops join) than a block nested loops join? Explain.
- If primary B+ indexes existed on R.a and S.b, would either provide a cheaper alternative for performing the join (using the index nested loops algorithm) than a block nested loops join? Explain.