Fig. 1: Fig. 1: (Left) Illustration of building the overlay network among the swicthes. (Right) NetFPGA-SUME Virtex-7 FPGA Development Board.
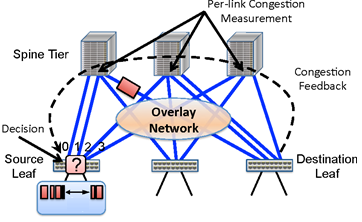

The purpose of this project is to study coordinated management of energy in data centers in all 3 major areas of the data center infrastructure: servers, data center network, and storage system. Our key objective is to consolidate the network traffic among few switch ports in a consistent manner, so that the rest of the switch ports can be put into sleep mode to conserve energy. To ensure this the candidate links are given ranks or priorities that are consistent throughout the network. Without any loss of generality, we assume that the candidate links at any switch are ranked from left-to-right, i.e. the flows are mostly consolidated to the leftmost links of the switches. (Although such an ordering is clear for the popular fat-tree network, we can define a similar consistent ordering for other networks as well.) During the low-traffic hours the left-most links (or ports) remain on, while the others can be put to sleep (i.e., in a low power mode such as LPI for Ethernet). We call this phase as consolidation phase. As the network traffic increases, some of the links are woken up gradually. This is the load-balancing phase.
The key challenge to realize this idea is when and how to transition between these two phases without any centralized entity. Recently programmable switches have been introduced that can add/delete headers and at the same time do some simple computation at the packet level. In our scheme we assume that the switches form an overlay network by encapsulating the packets emanating from the source rack and decapsulating them sending them to the destined rack. This encapsulation/decapsulation can be done using the standard encapsulation techniques like VXLAN or NVGRE. The encapsulated packets carry a parameter named max-load which carries the maximum load on any link through the path from source to destination rack. This parameter is updated by the programmable switches whenever the packet passes through them. The different paths in between different source and destination racks are numbered, as shown in Fig. 1. The encapsulated packet also carries the path number along with carrying the max-load. The destination switch records the max-load and the path number corresponding to the source switch, and send these back (a) either opportunistically piggybacking whenever it has any packet towards the source switch, or (b) by sending some extra control packets periodically. To ensure this, the leftmost links in between any source-destination switches remain always on for such opportunistic/periodic exchanges.
Our next objective is to explore how the dynamic replication of the hot data-chunks and intelligent routing of remote storage traffic can be used to simultaneously address the conflicting goals of congestion avoidance and consolidation. Ideally, the data-chunks used by an application should be located on the same node but this is not possible if (a) the desired IO rate or the storage space exceed the capacity of a single node, or (b) the storage is shared by multiple applications, not all of which can be placed on a single node due to application related limitations (e.g., inadequate computing power, memory bandwidth, memory size, etc.). Thus, the general problem is how to allocate applications and storage units used by them so that both application and storage related constraints are met and the network is not congested. This requires an intelligent placement of applications and data-chunks, coupled with dynamic data replication and migration of application to data copy association in order to avoid network congestion and yet consolidate network traffic to allow for efficient power management. Programmable switches can play an important role in this context, such as finding the heavy flows accessing certain replicas, or caching of certain hot replicas in case of key-value storage systems etc. We are currently working on netfpga sume (shown in Fig. 1) to attain more empirical credibility.
Related Publications: